Container > NHN Kubernetes Service(NKS) > 사용 가이드
클러스터
클러스터는 사용자의 Kubernetes를 구성하는 인스턴스들의 그룹입니다.
Kubernetes 버전 지원 정책
NKS의 Kubernetes 버전 지원 정책은 다음과 같습니다.
- 최신 Kubernetes 버전 지원
- NKS는 최신 Kubernetes 버전을 지속적으로 제공해 클러스터가 최신 버전을 유지할 수 있도록 합니다.
- 클러스터를 새로운 버전으로 생성하거나 기존 클러스터를 새로운 버전으로 업그레이드해 사용할 수 있습니다.
- 생성 가능 버전
- 클러스터로 생성 가능한 Kubernetes 버전은 4개로 유지됩니다.
- 따라서 생성 가능한 버전이 하나 추가되면 기존의 생성 가능 버전 목록에서 가장 낮은 버전이 제거됩니다.
- 서비스 지원 버전
- 서비스 지원이 종료된 버전을 사용하는 클러스터는 NKS의 신규 기능 동작을 보장하지 않습니다.
- NKS의 클러스터 버전 업그레이드 기능으로 클러스터의 Kubernetes 버전을 업그레이드할 수 있습니다.
- 서비스 지원 Kubernetes 버전은 5개로 유지됩니다.
- 따라서 생성 가능한 버전이 하나 추가되면 기존의 서비스 지원 가능 버전 목록에서 가장 낮은 버전이 제거됩니다.
각 Kubernetes 버전별 생성 가능 버전에 추가/삭제하는 시점과 서비스 지원 종료 시점은 다음과 같습니다. (단, 이 표는 2023년 9월 26일 기준으로 작성되었으며, 신규 생성 가능 버전의 버전명과 제공 시기는 당사 내부 사정에 의해 변경될 수 있습니다)
| 버전 | 생성 가능 버전에 추가 | 생성 가능 버전에서 제거 | 서비스 지원 종료 |
|---|---|---|---|
| v1.22.3 | 2022. 01. | 2023. 05. | 2023. 08. |
| v1.23.3 | 2022. 03. | 2023. 08. | 2024. 02. |
| v1.24.3 | 2022. 09. | 2024. 02. | 2024. 05.(예정) |
| v1.25.4 | 2023. 01. | 2024. 05.(예정) | 2024. 08.(예정) |
| v1.26.3 | 2023. 05. | 2024. 08.(예정) | 2025. 02.(예정) |
| v1.27.3 | 2023. 08. | 2025. 02.(예정) | 2025. 05.(예정) |
| v1.28.3 | 2024. 02. | 2025. 05.(예정) | 2025. 08.(예정) |
| v1.29.x | 2024. 05.(예정) | 2025. 08.(예정) | 2025. 11.(예정) |
클러스터 생성
NHN Kubernetes Service(NKS)를 사용하려면 먼저 클러스터를 생성해야 합니다.
[주의] 클러스터 사용을 위한 권한 설정
클러스터를 만들고자 하는 사용자는 대상 프로젝트에 대해 반드시 기본 인프라 서비스의 Infrastructure ADMIN 또는 Infrastructure LoadBalancer ADMIN 권한을 가져야 합니다. 해당 권한이 있어야만 기본 인프라 서비스를 기반으로 하는 클러스터를 정상적으로 생성하고 활용할 수 있으며, 이 중 하나의 권한을 가진 상태에서 다른 권한이 추가되는 것은 사용에 문제가 없습니다. 권한 설정에 대해서는 프로젝트 멤버 관리를 참고하세요. 클러스터 생성 시점의 권한 설정 내역이 차후 변경(임의의 권한 추가 혹은 삭제)될 경우 클러스터의 일부 기능 사용에 제한이 있을 수 있습니다. 이에 대한 자세한 내용은 클러스터 OWNER 변경을 참고하세요.
Container > NHN Kubernetes Service(NKS) 페이지에서 클러스터 생성을 클릭하면 클러스터 생성 페이지가 나타납니다. 클러스터 생성에 필요한 항목은 다음과 같습니다.
| 항목 | 설명 |
|---|---|
| 클러스터 이름 | Kubernetes 클러스터의 이름, 32자 이내로 영문 소문자와 숫자, '-'만 입력 가능하며 영문 소문자로 시작해야 하고 영문 소문자 또는 숫자로 끝나야 합니다. RFC 4122 표준의 UUID 형식은 사용할 수 없습니다. |
| Kubernetes 버전 | 사용할 Kubernetes 버전 |
| VPC | 클러스터에 연결할 VPC 네트워크 |
| 서브넷 | VPC에 정의된 서브넷 중 클러스터를 구성하는 인스턴스에 연결할 서브넷 |
| K8s 서비스 네트워크 | 클러스터의 service object CIDR 설정 |
| 파드 네트워크 | 클러스터의 파드 네트워크 설정 |
| 파드 서브넷 크기 | 클러스터의 파드 서브넷 크기 설정 |
| Kubernetes API 엔드포인트 | Public: 엔드포인트에 도메인 주소를 할당하고 플로팅 IP를 연결 Private: 엔드포인트를 내부 네트워크 주소로 설정 |
| 강화된 보안 규칙 | 워커 노드 보안 그룹 생성 시 필수 보안 규칙만 생성. 클러스터 워커 노드 필수 보안 규칙 항목 참고 True: 필수 보안 규칙만 생성 False: 필수 보안 규칙과 모든 포트를 허용하는 보안 규칙 생성 |
| 이미지 | 클러스터를 구성하는 인스턴스에 사용할 이미지 |
| 가용성 영역 | 기본 노드 그룹 인스턴스를 생성할 영역 |
| 인스턴스 타입 | 기본 노드 그룹 인스턴스 사양 |
| 노드 수 | 기본 노드 그룹 인스턴스 수 |
| 키 페어 | 기본 노드 그룹 접근에 사용할 키 페어 |
| 블록 스토리지 타입 | 기본 노드 그룹 인스턴스의 블록 스토리지 종류 |
| 블록 스토리지 크기 | 기본 노드 그룹 인스턴스의 블록 스토리지 크기 |
| 추가 네트워크 | 기본 워커 노드 그룹에 생성할 추가 네트워크/서브넷 |
[주의] VPC 네트워크 서브넷과 K8s 서비스 네트워크, 파드 네트워크의 CIDR은 경우 아래의 제약 사항에 해당하지 않도록 설정해야 합니다. - 링크 로컬 주소 대역(169.254.0.0/16)과 중첩될 수 없습니다. - VPC 네트워크 서브넷, 추가 네트워크 서브넷, 파드 네트워크와 K8s 서비스 네트워크 대역은 중첩될 수 없습니다. - NKS 내부에서 사용하고 있는 IP 대역(198.18.0.0/19)과 중첩될 수 없습니다. - /24보다 큰 CIDR 블록은 입력할 수 없습니다(다음과 같은 CIDR 블록은 사용할 수 없습니다. /26, /30). - v1.23.3 이하 클러스터의 경우 도커 BIP(bridged IP range)와 중첩될 수 없습니다(172.17.0.0/16).
[최대 생성 가능한 노드 수] 클러스터 생성 시 생성 가능한 최대 노드 수는 파드 네트워크, 파드 서브넷 크기 설정으로 결정됩니다. 계산법 : 2 ^ (파드 서브넷 크기 - 파드 네트워크의 호스트 비트) - 3 예제 : - 파드 서브넷 크기 = 24 - 파드 네트워크 = 10.100.0.0/16 - 계산 : 2 ^ (24 - 16) - 3 = 최대 253개 노드 생성 가능
[각 노드 당 파드에 할당 가능한 최대 IP 수] 한 개의 노드에서 사용 가능한 최대 IP수는 생성 가능한 최대 노드 수는 파드 서브넷 크기 설정으로 결정됩니다. 계산법 : 2 ^ (32 - pods_network_subnet) - 2 예제 : - 파드 서브넷 크기 = 24 - 계산 : 2 ^ (32 - 24) - 2 = 최대 254개 IP 사용 가능
[클러스터에서 파드에 할당 가능한 최대 IP 수] 계산법 : 각 노드 당 파드에 할당 가능한 최대 IP 수 * 최대 생성 가능한 노드 수 예제 : - 파드 서브넷 크기 = 24 - 파드 네트워크 = 10.100.0.0/16 - 계산 : 254(각 노드 당 파드에 할당 가능한 최대 IP 수) * 253(최대 생성 가능한 노드 수) = 최대 64,262개 IP 사용 가능
NHN Kubernetes Service(NKS)는 여러 가지 버전을 지원합니다. 버전에 따라 일부 기능에 제약이 있을 수 있습니다.
| 버전 | 클러스터 신규 생성 | 생성된 클러스터 사용 |
|---|---|---|
| v1.17.6 | 불가능 | 가능 |
| v1.18.19 | 불가능 | 가능 |
| v1.19.13 | 불가능 | 가능 |
| v1.20.12 | 불가능 | 가능 |
| v1.21.6 | 불가능 | 가능 |
| v1.22.3 | 불가능 | 가능 |
| v1.23.3 | 불가능 | 가능 |
| v1.24.3 | 불가능 | 가능 |
| v1.25.4 | 가능 | 가능 |
| v1.26.3 | 가능 | 가능 |
| v1.27.3 | 가능 | 가능 |
NHN Kubernetes Service(NKS)는 버전에 따라 다른 종류의 Container Network Interface(CNI)를 제공합니다. 2023/04/04 이후에는 v1.24.3 버전 이상의 클러스터 생성 시 CNI가 Calico로 생성됩니다. Flannel과 Calico CNI의 Network mode는 모두 VXLAN 방식으로 동작합니다.
| 버전 | 클러스터 생성 시 설치한 CNI 종류 및 버전 | CNI 변경 가능 여부 |
|---|---|---|
| v1.17.6 | Flannel v0.12.0 | 불가 |
| v1.18.19 | Flannel v0.12.0 | 불가 |
| v1.19.13 | Flannel v0.14.0 | 불가 |
| v1.20.12 | Flannel v0.14.0 | 불가 |
| v1.21.6 | Flannel v0.14.0 | 불가 |
| v1.22.3 | Flannel v0.14.0 | 불가 |
| v1.23.3 | Flannel v0.14.0 | 불가 |
| v1.24.3 | Flannel v0.14.0 혹은 Calico v3.24.1 1 | 조건부 가능 2 |
| v1.25.4 | Flannel v0.14.0 혹은 Calico v3.24.1 1 | 조건부 가능 2 |
| v1.26.3 | Flannel v0.14.0 혹은 Calico v3.24.1 1 | 조건부 가능 2 |
| v1.27.3 | Calico v3.24.1 | 불가 |
| v1.28.3 | Calico v3.24.1 | 불가 |
주석
- 1: 2023/03/31 이전에 생성된 클러스터에는 Flannel이 설치되어 있습니다. 2023/03/31 이후에 생성되는 v1.24.3 이상의 클러스터는 Calico가 설치됩니다.
- 2: CNI 변경은 v1.24.3 이상의 클러스터에서만 지원되며, 현재 Flannel에서 Calico로의 변경만 지원합니다.
클러스터 워커 노드 필수 보안 규칙 항목
| 방향 | IP 프로토콜 | 포트 범위 | Ether | 원격 | 설명 | 특이 사항 |
|---|---|---|---|---|---|---|
| ingress | TCP | 10250 | IPv4 | 워커 노드 | kubelet 포트, 방향: metrics-server(worker node) -> kubelet(worker node) | |
| ingress | TCP | 10250 | IPv4 | 마스터 노드 | kubelet 포트, 방향: kube-apiserver(NKS Control plane) -> kubelet(worker node) | |
| ingress | TCP | 5473 | IPv4 | 워커 노드 | calico-typha 포트, 방향: calico-node(worker node) -> calico-typha(worker node) | CNI가 calico인 경우 생성 |
| ingress | UDP | 8472 | IPv4 | 워커 노드 | flannel vxlan overlay network 포트, 방향: pod(worker node) -> pod(worker node) | CNI가 flannel인 경우 생성됨 |
| ingress | UDP | 8472 | IPv4 | 워커 노드 | flannel vxlan overlay network 포트, 방향: pod(NKS Control plane) -> pod(worker node) | CNI가 flannel인 경우 생성됨 |
| ingress | UDP | 4789 | IPv4 | 워커 노드 | calico-node vxlan overlay network 포트, 방향: pod(worker node) -> pod(worker node) | CNI가 calico인 경우 생성됨 |
| ingress | UDP | 4789 | IPv4 | 마스터 노드 | calico-node vxlan overlay network 포트, 방향: pod(NKS Control plane) -> pod(worker node) | CNI가 calico인 경우 생성됨 |
| egress | TCP | 2379 | IPv4 | 마스터 노드 | etcd 포트, 방향: calico-kube-controller(worker node) -> etcd(NKS Control plane) | |
| egress | TCP | 6443 | IPv4 | Kubernetes API 엔드포인트 | kube-apiserver 포트, 방향: kubelet, kube-proxy(worker node) -> kube-apiserver(NKS Control plane) | |
| egress | TCP | 6443 | IPv4 | 마스터 노드 | kube-apiserver 포트, 방향: default kubernetes service(worker node) -> kube-apiserver(NKS Control plane) | |
| egress | TCP | 5473 | IPv4 | 워커 노드 | CNI가 calico인 경우 생성됨, calico-typha 포트, 방향: calico-node(worker node) -> calico-typha(worker node) | |
| egress | TCP | 53 | IPv4 | 워커 노드 | DNS 포트, 방향: worker node -> external | |
| egress | TCP | 443 | IPv4 | 모두 허용 | HTTPS 포트, 방향: worker node -> external | |
| egress | TCP | 80 | IPv4 | 모두 허용 | HTTP 포트, 방향: worker node -> external | |
| egress | UDP | 8472 | IPv4 | 워커 노드 | flannel vxlan overlay network 포트, 방향: pod(worker node) -> pod(worker node) | CNI가 flannel인 경우 생성됨 |
| egress | UDP | 8472 | IPv4 | 마스터 노드 | flannel vxlan overlay network 포트, 방향: pod(worker node) -> pod(NKS Control plane) | CNI가 flannel인 경우 생성됨 |
| egress | UDP | 4789 | IPv4 | 워커 노드 | calico-node vxlan overlay network 포트, 방향: pod(worker node) -> pod(worker node) | CNI가 calico인 경우 생성됨 |
| egress | UDP | 4789 | IPv4 | 마스터 노드 | calico-node vxlan overlay network 포트, 방향: pod(worker node) -> pod(NKS Control plane) | CNI가 calico인 경우 생성됨 |
| egress | UDP | 53 | IPv4 | 모두 허용 | DNS 포트, 방향: worker node -> external |
강화된 보안 규칙 사용 시 NodePort 타입의 서비스와 NHN Cloud NAS 서비스에서 사용하는 포트에 대한 보안 규칙에 추가되어 있지 않습니다. 필요에 따라 아래 보안 규칙을 추가 설정해야 합니다.
| 방향 | IP 프로토콜 | 포트 범위 | Ether | 원격 | 설명 |
|---|---|---|---|---|---|
| ingress, egress | TCP | 30000 - 32767 | IPv4 | 모두 허용 | NKS service object NodePort, 방향: external -> worker node |
| egress | TCP | 2049 | IPv4 | NHN Cloud NAS 서비스 IP주소 | csi-nfs-node의 rpc nfs 포트, 방향: csi-nfs-node(worker node) -> NHN Cloud NAS 서비스 |
| egress | TCP | 111 | IPv4 | NHN Cloud NAS 서비스 IP주소 | csi-nfs-node의 rpc portmapper 포트, 방향: csi-nfs-node(worker node) -> NHN Cloud NAS 서비스 |
| egress | TCP | 635 | IPv4 | NHN Cloud NAS 서비스 IP주소 | csi-nfs-node의 rpc mountd 포트, 방향: csi-nfs-node(worker node) -> NHN Cloud NAS 서비스 |
강화된 보안 규칙을 사용하지 않는 경우 NodePort 타입의 서비스와 외부 네트워크 통신에 필요한 보안 규칙이 추가로 생성됩니다.
| 방향 | IP 프로토콜 | 포트 범위 | Ether | 원격 | 설명 |
|---|---|---|---|---|---|
| ingress | TCP | 1 - 65535 | IPv4 | 워커 노드 | 모든 포트, 방향: worker node -> worker node |
| ingress | TCP | 1 - 65535 | IPv4 | 마스터 노드 | 모든 포트, 방향: NKS Control plane -> worker node |
| ingress | TCP | 30000 - 32767 | IPv4 | 모두 허용 | NKS service object NodePort, 방향: external -> worker node |
| ingress | UDP | 1 - 65535 | IPv4 | 워커 노드 | 모든 포트, 방향: worker node -> worker node |
| ingress | UDP | 1 - 65535 | IPv4 | 마스터 노드 | 모든 포트, 방향: NKS Control plane -> worker node |
| egress | 임의 | 1 - 65535 | IPv4 | 모두 허용 | 모든 포트, 방향: worker node - > external |
| egress | 임의 | 1 - 65535 | IPv6 | 모두 허용 | 모든 포트, 방향: worker node - > external |
필요한 정보를 입력하고 클러스터 생성을 클릭하면 클러스터 생성이 시작됩니다. 클러스터 목록에서 상태를 확인할 수 있습니다. 생성하는 데는 약 10분 정도 걸립니다. 클러스터 설정에 따라 더 오래 걸릴 수도 있습니다.
클러스터 조회
생성한 클러스터는 Container > NHN Kubernetes Service(NKS) 페이지에서 확인할 수 있습니다. 클러스터 목록에는 각 클러스터에 대한 간략한 정보가 나타납니다.
| 항목 | 설명 |
|---|---|
| 클러스터 이름 | 클러스터의 이름 |
| 노드 수 | 클러스터의 전체 워커 노드 수 |
| Kubernetes 버전 | Kubernetes 버전 정보 |
| kubeconfig 파일 | 클러스터를 제어하기 위한 kubeconfig 파일 다운로드 버튼 |
| 작업 상태 | 클러스터에 내린 명령에 대한 작업 상태 |
| k8s API 상태 | Kubernetes API 엔드포인트의 동작 상태 |
| k8s Node 상태 | Kubernetes Node 리소스의 상태 |
작업 상태의 아이콘 별 의미는 다음과 같습니다.
| 아이콘 | 의미 |
|---|---|
| 초록색 솔리드 아이콘 | 작업 정상 종료 |
| 원형 회전 아이콘 | 작업 진행 중 |
| 빨간색 솔리드 아이콘 | 작업 실패 |
| 회색 솔리드 아이콘 | 클러스터 사용 불가능 |
k8s API 상태의 아이콘 별 의미는 다음과 같습니다.
| 아이콘 | 의미 |
|---|---|
| 초록색 솔리드 아이콘 | 정상 동작 중 |
| 노란색 솔리드 아이콘 | 정보의 유효 기간(5분)이 얼마 남지 않아 정보가 정확하지 않음 |
| 빨간색 솔리드 아이콘 | Kubernetes API 엔드포인트가 정상 동작하지 않거나 정보의 유효 기간이 만료됐음 |
k8s Node 상태의 아이콘 별 의미는 다음과 같습니다.
| 아이콘 | 의미 |
|---|---|
| 초록색 솔리드 아이콘 | 클러스터의 모든 노드가 Ready 상태임 |
| 노란색 솔리드 아이콘 | Kubernetes API 엔드포인트가 정상 동작하지 않거나 클러스터 내에 NotReady 상태인 노드가 존재함 |
| 빨간색 솔리드 아이콘 | 클러스터의 모든 노드가 NotReady 상태임 |
클러스터를 선택하면 하단에 클러스터 정보가 나타납니다.
| 항목 | 설명 |
|---|---|
| 클러스터 이름 | Kubernetes 클러스터의 이름과 ID |
| 노드 수 | 클러스터를 구성하는 모든 노드 인스턴스 수 |
| Kubernetes 버전 | 사용 중인 Kubernetes 버전 |
| CNI | 사용 중인 Kubernetes CNI 종류 |
| K8s 서비스 네트워크 | 클러스터의 service object CIDR 설정 |
| 파드 네트워크 | 사용 중인 Kubernetes 파드 네트워크 설정 |
| 파드 서브넷 크기 | 사용 중인 Kubernetes 파드 서브넷 크기 설정 |
| VPC | 클러스터에 연결된 VPC 네트워크 |
| 서브넷 | 클러스터를 구성하는 노드 인스턴스에 연결된 서브넷 |
| API 엔드포인트 | 클러스터에 접근해 조작하기 위한 API 엔드포인트 URI |
| 설정 파일 | 클러스터에 접근해 조작하기 위해 필요한 설정 파일 다운로드 버튼 |
클러스터 삭제
삭제할 클러스터를 선택하고 클러스터 삭제를 클릭하면 삭제가 진행됩니다. 삭제하는 데는 약 5분 정도 걸립니다. 클러스터의 상태에 따라 더 오래 걸릴 수도 있습니다.
클러스터 OWNER 변경
[참고] 기본적으로 클러스터 OWNER는 클러스터를 생성한 사용자를 의미하지만, 상황에 따라 다른 사용자로 변경 가능합니다.
클러스터는 생성 시점의 OWNER 권한을 기반으로 동작합니다. 해당 권한은 Kubernetes와 NHN Cloud 기본 인프라 서비스의 연동 과정에서 사용됩니다. Kubernetes에서 사용하는 기본 인프라 서비스는 다음과 같습니다.
| 기본 인프라 서비스 | Kubernetes와의 연동 |
|---|---|
| Compute | Kubernetes 클러스터 오토스케일러를 통한 워커 노드 증설 혹은 감축 시 Instance 서비스 사용 |
| Network | Kubernetes LoadBalancer 서비스 생성 시 Load Balancer 및 Floating IP 서비스 사용 |
| Storage | Kubernetes 퍼시스턴트 볼륨 생성 시 Block Storage 서비스 사용 |
동작 중 아래와 같은 상황이 발생할 경우 Kubernetes에서 기본 인프라 서비스를 사용할 수 없게 됩니다.
| 상황 | 사례 |
|---|---|
| 프로젝트에서 클러스터 OWNER 이탈 | 클러스터 OWNER의 퇴사로 인한 프로젝트 멤버 제거 혹은 인위적 프로젝트 멤버 제거 |
| 클러스터 OWNER의 권한 변경 | 클러스터 생성 시점 이후 임의의 권한 추가 혹은 삭제 |
위와 같은 이유로 클러스터 운용에 문제가 발생하고, 멤버나 권한 설정을 통해 정상화할 수 없을 경우 NKS 콘솔의 클러스터 OWNER 변경 기능을 이용해 정상화할 수 있습니다. 클러스터 OWNER 변경 기능 사용법은 다음과 같습니다.
[참고] 콘솔에서 클러스터 OWNER 변경 작업을 수행하는 사용자가 대상 클러스터의 새로운 OWNER가 됩니다. OWNER 변경 작업 완료 이후의 클러스터는 새로운 OWNER의 권한을 기반으로 동작합니다.
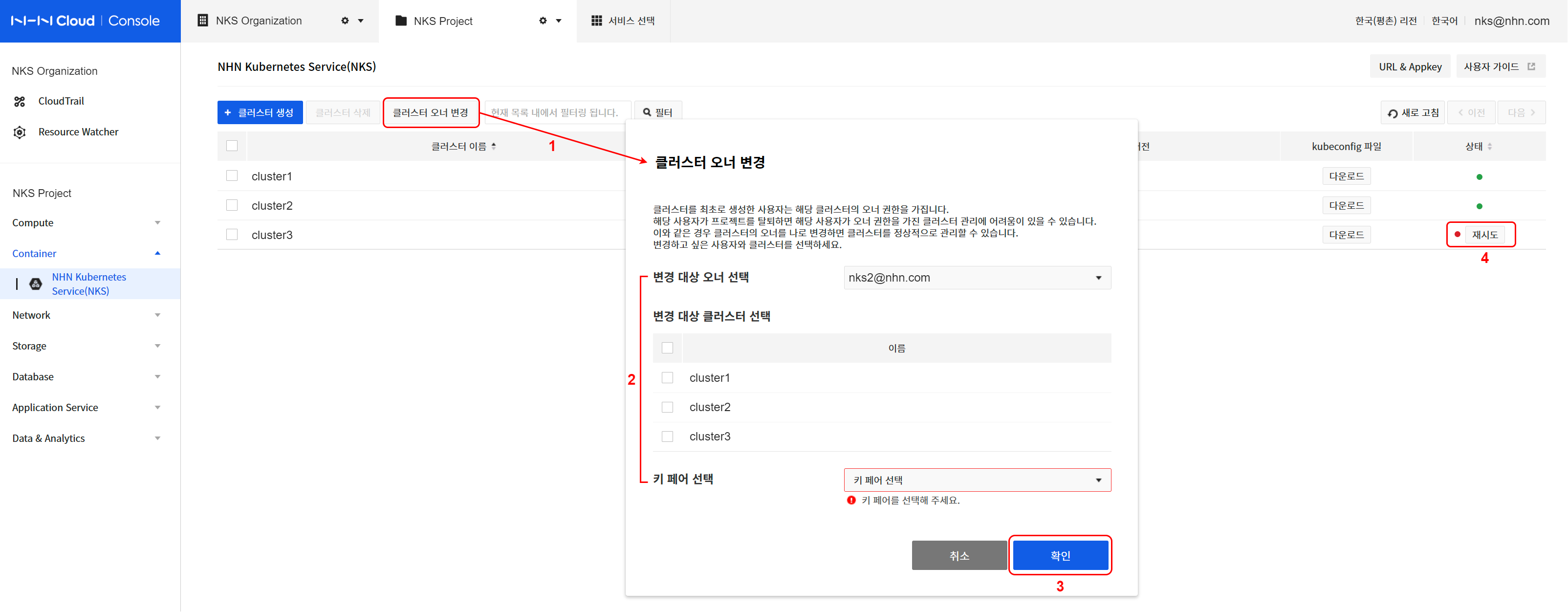
- 클러스터 오너 변경을 클릭합니다.
- 변경 대상 오너 및 클러스터를 지정합니다.
- 변경 대상 클러스터를 특정하기 위한 현재의 오너를 지정합니다.
- 노출된 클러스터 목록에서 변경 대상을 선택합니다.
- 신규 워커 노드 생성 시 사용할 자신의 키 페어를 지정합니다.
- 오너 변경을 진행하려면 확인을 클릭합니다.
- 변경 대상 클러스터의 상태를 확인합니다.
- NKS 콘솔의 클러스터 목록에서 지정한 클러스터들에 대한 작업 진행 상태를 확인합니다.
- OWNER 변경 작업 진행 중인 클러스터의 상태는 HANDOVER_IN_PROGRESS이며, 정상적으로 완료된 경우 HANDOVER_COMPLETE 상태로 전환됩니다.
- 해당 클러스터 하위의 모든 노드 그룹도 HANDOVER_* 상태로 전환됩니다.
- 작업에 문제가 발생한 경우에는 HANDOVER_FAILED 상태로 전환되며, 정상화 전까지 클러스터 형상 변경 작업(노드 추가 등)은 허용되지 않습니다.
- 이와 같은 상태의 클러스터에는 상태 아이콘 옆에 재시도 버튼이 노출됩니다.
- 클러스터 상태 정상화를 위해 재시도를 클릭하고, 키 페어를 지정한 뒤 확인을 클릭합니다.
[주의] 클러스터 OWNER 변경과 키 페어
NHN Cloud 기본 인프라 서비스의 키 페어 리소스는 특정 사용자에게 종속되며, 다른 사용자와 공유할 수 없습니다. (NHN Cloud 콘솔에서 키 페어 생성 후 다운로드한 PEM 파일과는 별개) 따라서 클러스터를 생성할 때 지정된 키 페어 리소스 또한 클러스터 OWNER 변경 시 신규 OWNER의 것으로 새롭게 지정해야 합니다.
클러스터 OWNER 변경 후 생성된 워커 노드(인스턴스)에는 새롭게 지정된 키 페어(PEM 파일)를 이용해 접속할 수 있습니다. 하지만 OWNER 변경 전에 만들어진 워커 노드에 접속하려면 여전히 기존 OWNER의 키 페어(PEM 파일)가 필요합니다. 따라서 OWNER를 변경하더라도 기존 키 페어(PEM 파일)는 프로젝트 관리자 수준에서 잘 관리해 주셔야 합니다.
노드 그룹
노드 그룹은 Kubernetes를 구성하는 워커 노드 인스턴스들의 그룹입니다.
노드 그룹 조회
클러스터 목록에서 클러스터 이름을 클릭하면 노드 그룹 목록을 확인할 수 있습니다. 노드 그룹 목록에는 각 노드 그룹에 대한 간략한 정보가 나타납니다.
| 항목 | 설명 |
|---|---|
| 노드 그룹 이름 | 노드 그룹의 이름 |
| 노드 수 | 노드 그룹에 속한 노드 수 |
| Kubernetes 버전 | 노드 그룹에 적용된 Kubernetes 버전 정보 |
| 가용성 영역 | 노드 그룹에 적용된 가용성 영역 정보 |
| 인스턴스 타입 | 노드 그룹의 인스턴스 타입 |
| 이미지 타입 | 노드 그룹의 이미지 타입 |
| 작업 상태 | 노드 그룹에 내린 명령에 대한 작업 상태 |
| k8s Node 상태 | 노드 그룹에 속한 Kubernetes Node 리소스의 상태 |
작업 상태의 아이콘 별 의미는 다음과 같습니다.
| 아이콘 | 의미 |
|---|---|
| 초록색 솔리드 아이콘 | 작업 정상 종료 |
| 원형 회전 아이콘 | 작업 진행 중 |
| 빨간색 솔리드 아이콘 | 작업 실패 |
| 회색 솔리드 아이콘 | 클러스터 및 노드 그룹 사용 불가능 |
k8s Node 상태의 아이콘 별 의미는 다음과 같습니다.
| 아이콘 | 의미 |
|---|---|
| 초록색 솔리드 아이콘 | 노드 그룹의 모든 노드가 Ready 상태임 |
| 노란색 솔리드 아이콘 | Kubernetes API 엔드포인트가 정상 동작하지 않거나 노드 그룹 내에 NotReady 상태인 노드가 존재함 |
| 빨간색 솔리드 아이콘 | 노드 그룹의 모든 노드가 NotReady 상태임 |
노드 그룹을 선택하면 하단에 노드 그룹 정보가 나타납니다.
- 기본 정보 기본 정보 탭에서는 다음과 정보를 확인할 수 있습니다.
| 항목 | 설명 |
|---|---|
| 노드 그룹 이름 | 노드 그룹 이름과 ID |
| 클러스터 이름 | 노드 그룹이 속한 클러스터의 이름과 ID |
| Kubernetes 버전 | 사용 중인 Kubernetes 버전 |
| 가용성 영역 | 노드 그룹 인스턴스가 생성된 영역 |
| 인스턴스 타입 | 노드 그룹 인스턴스 사양 |
| 이미지 타입 | 노드 그룹 인스턴스에 사용한 이미지 종류 |
| 블록 스토리지 크기 | 노드 그룹 인스턴스의 블록 스토리지 크기 |
| 생성일 | 노드 그룹이 생성된 시각 |
| 수정일 | 노드 그룹이 마지막으로 수정된 시각 |
- 노드 목록 노드 목록 탭에서는 노드 그룹을 구성하는 인스턴스의 목록을 확인할 수 있습니다.
노드 그룹 생성
클러스터를 생성하면 기본 노드 그룹이 생성되지만, 필요에 따라 추가 노드 그룹을 만들 수 있습니다. 기본 노드 그룹의 인스턴스보다 높은 사양의 컨테이너 구동 환경이 필요하거나, 스케일 아웃(scale out, 확장)을 위해 더 많은 워커 노드 인스턴스가 필요한 경우 추가 노드 그룹을 생성해 사용할 수 있습니다. 노드 그룹 목록 페이지에서 노드 그룹 생성 버튼을 클릭하면 노드 그룹 생성 페이지가 나타납니다. 노드 그룹 생성에 필요한 항목은 다음과 같습니다.
| 항목 | 설명 |
|---|---|
| 가용성 영역 | 클러스터를 구성하는 인스턴스를 생성할 영역 |
| 노드 그룹 이름 | 추가 노드 그룹 이름, 32자 이내로 영문 소문자와 숫자, '-'만 입력 가능하며 영문 소문자로 시작해야 하고 영문 소문자 또는 숫자로 끝나야 합니다. RFC 4122 표준의 UUID 형식은 사용할 수 없습니다. |
| 인스턴스 타입 | 추가 노드 그룹 인스턴스 사양 |
| 노드 수 | 추가 노드 그룹 인스턴스 수 |
| 키 페어 | 추가 노드 그룹 접근에 사용할 키 페어 |
| 블록 스토리지 타입 | 추가 노드 그룹 인스턴스의 블록 스토리지 종류 |
| 블록 스토리지 크기 | 추가 노드 그룹 인스턴스의 블록 스토리지 크기 |
| 추가 네트워크 | 기본 워커 노드 그룹에 생성할 추가 네트워크/서브넷 |
필요한 정보를 입력하고 노드 그룹 생성 버튼을 클릭하면 노드 그룹 생성이 시작됩니다. 노드 그룹 목록에서 상태를 확인할 수 있습니다. 노드 그룹 생성하는 데는 약 5분 정도 걸립니다. 노드 그룹 설정에 따라 더 오래 걸릴 수도 있습니다.
[주의] 해당 클러스터를 생성한 사용자만 노드 그룹 생성이 가능합니다.
노드 그룹 삭제
노드 그룹 목록에서 삭제하려는 노드 그룹을 선택하고 노드 그룹 삭제 버튼을 클릭하면 삭제가 진행됩니다. 노드 그룹 삭제하는 데는 약 5분 정도 걸립니다. 노드 그룹의 상태에 따라 더 오래 걸릴 수도 있습니다.
노드 그룹에 노드 추가
동작 중인 노드 그룹에 노드를 추가할 수 있습니다. 노드 그룹 정보 조회 페이지의 노드 목록 탭을 클릭하면 현재 노드 목록이 나타납니다. 노드 추가 버튼을 클릭하고 노드 수를 입력하면 노드가 추가됩니다.
[주의] 오토 스케일러가 활성화된 노드 그룹은 수동으로 노드를 추가할 수 없습니다.
노드 그룹에서 노드 삭제
동작 중인 노드 그룹에서 노드를 삭제할 수 있습니다. 노드 그룹 정보 조회 페이지의 노드 목록 탭을 클릭하면 현재 노드 목록이 나타납니다. 노드 목록 중 삭제할 노드를 선택하고 노드 삭제 버튼을 클릭하면 확인 대화 상자가 나타납니다. 삭제할 노드 이름을 다시 한번 확인하고 확인 버튼을 클릭하면 노드가 삭제됩니다.
[주의] 삭제되는 노드에서 동작하고 있던 파드는 강제 종료 됩니다. 삭제될 노드에서 동작 중인 파드를 안전하게 다른 노드로 옮기기 위해서는 drain 명령을 내려야 합니다. 노드가 drain 된 후에도 새로운 파드는 이 노드에 스케줄링 될 수 있습니다. 새로운 파드가 삭제될 노드에 스케줄링되는 것을 방지하기 위해서는 cordon 명령을 내려야 합니다. 안전한 노드 관리에 대한 좀 더 자세한 내용은 아래 문서를 참고하세요.
[주의] 오토 스케일러가 활성화된 노드 그룹은 수동으로 노드를 삭제할 수 없습니다.
노드 중지와 시작
노드 그룹에 속한 노드 중 일부를 중지시키고, 중지된 노드를 다시 시작할 수 있습니다. 노드 그룹 정보 조회 페이지의 노드 목록 탭을 클릭하면 현재 노드 목록이 나타납니다. 중지할 노드를 선택하고 노드 중지 버튼을 클릭하면 노드가 중지됩니다. 중지된 노드를 선택하고 노드 시작 버튼을 클릭하면 노드가 다시 시작됩니다.
동작 과정
시작 상태의 노드를 중지하면 다음의 순서로 동작합니다.
- 해당 노드가 drain 됩니다.
- 해당 노드가 Kubernetes 노드 자원에서 삭제됩니다.
- 해당 노드를 인스턴스 수준에서 SHUTDOWN 상태로 만듭니다.
중지 상태의 노드를 시작하면 다음의 순서로 동작합니다. * 해당 노드를 인스턴스 수준에서 ACTIVE 상태로 만듭니다. * 해당 노드가 Kubernetes 노드 자원에 다시 추가됩니다.
제약 사항
노드 중지와 시작 기능은 다음의 제약 사항이 있습니다.
- 시작 상태의 노드를 중지할 수 있고, 중지 상태의 노드를 시작할 수 있습니다.
- 워커 노드 그룹 내의 모든 노드를 중지할 수는 없습니다.
- 오토 스케일러가 활성화된 노드 그룹은 노드를 중지할 수 없습니다.
- 중지된 노드가 존재하는 노드 그룹은 오토 스케일러를 활성화할 수 없습니다.
- 중지된 노드가 존재하는 노드 그룹은 업그레이드를 할 수 없습니다.
상태 표시
노드의 상태에 따라 노드 목록 탭의 상태 아이콘이 표시됩니다. 아이콘 색상별 상태는 다음과 같습니다.
- 초록색: 시작 상태의 노드
- 회색: 중지 상태의 노드
- 빨간색: 비정상 상태의 노드
GPU 노드 그룹 사용
Kubernetes를 통한 GPU 기반 워크로드 실행이 필요한 경우, GPU 인스턴스로 구성된 노드 그룹을 생성할 수 있습니다.
클러스터 혹은 노드 그룹 생성 과정에서 인스턴스 타입 선택 시, g2 타입을 선택하면 GPU 노드 그룹을 만들 수 있습니다.
[참고] NHN Cloud GPU 인스턴스에서 제공되는 GPU는 NVIDIA 계열입니다. (사용 가능한 GPU 제원 확인하기) NVIDIA GPU 이용을 위해 Kubernetes에 필요한 nvidia-device-plugin은 GPU 노드 그룹 생성 시 자동으로 설치됩니다.
생성된 GPU 노드에 대한 기본적인 설정 상태 확인 및 간단한 동작 테스트는 다음과 같은 방법을 이용하면 됩니다.
노드 수준의 상태 확인
GPU 노드에 접속한 후, nvidia-smi 명령을 실행합니다.
다음과 같은 내용이 출력되면 GPU driver가 정상적으로 동작하는 것입니다.
$ nvidia-smi
Mon Jul 27 14:38:07 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.152.00 Driver Version: 418.152.00 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:05.0 Off | 0 |
| N/A 30C P8 9W / 70W | 0MiB / 15079MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Kubernetes 수준의 상태 확인
kubectl 명령을 사용해 클러스터 수준에서 사용 가능한 GPU 리소스 정보를 확인합니다.
아래는 각 노드에서 사용 가능한 GPU 코어의 개수를 출력하도록 하는 명령 및 수행 결과입니다.
$ kubectl get nodes -A -o custom-columns='NAME:.metadata.name,GPU Allocatable:.status.allocatable.nvidia\.com/gpu,GPU Capacity:.status.capacity.nvidia\.com/gpu'
NAME GPU Allocatable GPU Capacity
my-cluster-default-w-vdqxpwisjjsk-node-1 1 1
GPU 테스트를 위한 샘플 워크로드 실행
Kubernetes 클러스터에 속한 GPU 노드들은 CPU와 메모리 이외에 nvidia.com/gpu와 같은 이름의 리소스를 제공합니다.
GPU를 사용하고 싶다면 nvidia.com/gpu 리소스를 할당받도록 아래의 샘플 파일처럼 입력하면 됩니다.
- resnet.yaml
apiVersion: v1
kind: Pod
metadata:
name: resnet-gpu-pod
spec:
imagePullSecrets:
- name: nvcr.dgxkey
containers:
- name: resnet
image: nvcr.io/nvidia/tensorflow:18.07-py3
command: ["mpiexec"]
args: ["--allow-run-as-root", "--bind-to", "socket", "-np", "1", "python", "/opt/tensorflow/nvidia-examples/cnn/resnet.py", "--layers=50", "--precision=fp16", "--batch_size=64", "--num_iter=90"]
resources:
limits:
nvidia.com/gpu: 1
위 파일을 실행하면 다음과 같은 결과를 확인할 수 있습니다.
$ kubectl create -f resnet.yaml
pod/resnet-gpu-pod created
$ kubectl get pods resnet-gpu-pod
NAME READY STATUS RESTARTS AGE
resnet-gpu-pod 0/1 Running 0 17s
$ kubectl logs resnet-gpu-pod -n default -f
PY 3.5.2 (default, Nov 23 2017, 16:37:01)
[GCC 5.4.0 20160609]
TF 1.8.0
Script arguments:
--layers 50
--display_every 10
--iter_unit epoch
--batch_size 64
--num_iter 100
--precision fp16
Training
WARNING:tensorflow:Using temporary folder as model directory: /tmp/tmpjw90ypze
2020-07-31 00:57:23.020712: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:898] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-07-31 00:57:23.023190: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1356] Found device 0 with properties:
name: Tesla T4 major: 7 minor: 5 memoryClockRate(GHz): 1.59
pciBusID: 0000:00:05.0
totalMemory: 14.73GiB freeMemory: 14.62GiB
2020-07-31 00:57:23.023226: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1435] Adding visible gpu devices: 0
2020-07-31 00:57:23.846680: I tensorflow/core/common_runtime/gpu/gpu_device.cc:923] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-07-31 00:57:23.846743: I tensorflow/core/common_runtime/gpu/gpu_device.cc:929] 0
2020-07-31 00:57:23.846753: I tensorflow/core/common_runtime/gpu/gpu_device.cc:942] 0: N
2020-07-31 00:57:23.847023: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 14151 MB memory) -> physical GPU (device: 0, name: Tesla T4, pci bus id: 0000:00:05.0, compute capability: 7.5)
Step Epoch Img/sec Loss LR
1 1.0 3.1 7.936 8.907 2.00000
10 10.0 68.3 1.989 2.961 1.65620
20 20.0 214.0 0.002 0.978 1.31220
30 30.0 213.8 0.008 0.979 1.00820
40 40.0 210.8 0.095 1.063 0.74420
50 50.0 211.9 0.261 1.231 0.52020
60 60.0 211.6 0.104 1.078 0.33620
70 70.0 211.3 0.340 1.317 0.19220
80 80.0 206.7 0.168 1.148 0.08820
90 90.0 210.4 0.092 1.073 0.02420
100 100.0 210.4 0.001 0.982 0.00020
[참고] GPU가 필요없는 워크로드가 GPU 노드에 할당되는 것을 막고 싶다면 Taint 및 Toleration 개요를 참고하세요.
오토 스케일러
오토 스케일러는 노드 그룹의 가용 리소스가 부족해 파드(pod)를 스케줄링할 수 없거나 노드의 사용률이 일정 수준 이하로 유지되는 경우 노드의 수를 자동으로 조정하는 기능입니다. 이 기능은 노드 그룹별로 설정할 수 있고, 서로 독립적으로 동작합니다. 이 기능은 Kubernetes 프로젝트의 공식 지원 기능인 cluster-autoscaler 기능을 기반으로 합니다. 자세한 사항은 Cluster Autoscaler를 참고하세요.
[참고] NHN Kubernetes Service(NKS)에 적용된
cluster-autoscaler의 버전은1.19.0입니다.
용어 정리
오토 스케일러 기능에서 사용하는 용어와 그 의미는 다음과 같습니다.
| 용어 | 의미 |
|---|---|
| 증설 | 노드의 수를 증가시키는 것을 말합니다 |
| 감축 | 노드의 수를 감소시키는 것을 말합니다 |
오토 스케일러 설정
오토 스케일러 기능은 노드 그룹별로 설정하고 동작합니다. 오토 스케일러 기능은 아래 경로로 설정할 수 있습니다.
- 클러스터 생성 시 기본 노드 그룹에 설정
- 노드 그룹 추가 시 추가 노드 그룹에 설정
- 생성되어 있는 노드 그룹에 설정
오토 스케일러 활성화 시 아래의 항목에 대해 설정할 수 있습니다.
| 설정 항목 | 의미 | 유효 범위 | 기본값 | 단위 |
|---|---|---|---|---|
| 최소 노드 수 | 감축 가능한 최소 노드 수 | 1-10 | 1 | 대 |
| 최대 노드 수 | 증설 가능한 최대 노드 수 | 1-10 | 10 | 대 |
| 감축 | 노드 감축 활성 여부 설정 | 활성/비활성 | 활성 | - |
| 리소스 사용량 임계치 | 감축의 기준인 리소스 사용량 임계 영역의 기준값 | 1-100 | 50 | % |
| 임계 영역 유지 시간 | 감축 대상이 될 노드의 임계치 이하의 리소스 사용량 유지 시간 | 1-1440 | 10 | 분 |
| 증설 후 감축 지연 시간 | 노드 증설 후 감축 대상 노드로 모니터링하기 시작까지의 지연 시간 | 10-1440 | 10 | 분 |
[주의] 오토 스케일러가 활성화된 노드 그룹은 수동으로 노드를 추가하거나 삭제할 수 없습니다.
증설 및 감축 조건
아래의 조건을 모두 만족하면 노드를 증설합니다.
- 파드가 스케줄링될 수 있는 노드가 없음
- 현재 노드 수가 최대 노드 수보다 작음
아래의 조건을 모두 만족하면 노드를 감축합니다.
- 노드의 리소스 사용량이 임계치 이하로 임계 영역 유지 시간 동안 유지
- 현재 노드 수가 최소 노드 수보다 큼
특정 노드에 아래 조건을 만족하는 파드가 하나라도 존재한다면 해당 노드는 노드 감축 후보에서 제외됩니다.
- "PodDisruptionBudget"으로 제약 받는 파드
- "kube-system" 네임스페이스의 파드
- "deployment", "replicaset" 등의 제어 오브젝트에 의해 시작되지 않은 파드
- 로컬 스토리지를 사용하는 파드
- "node selector" 등의 제약으로 인해 다른 노드로 이동이 불가능한 파드
좀 더 자세한 증설 및 감축 조건은 Cluster Autoscaler FAQ를 참고하세요.
동작 예시
오토 스케일러의 동작을 예시를 통해 알아봅니다.
1. 오토 스케일러 활성화
대상 클러스터의 기본 노드 그룹의 오토 스케일러 기능을 활성화 합니다. 이 예시에서는 기본 노드 그룹의 노드 수를 1로 생성하였고, 오토 스케일러 설정 항목은 아래와 같이 설정했습니다.
| 설정 항목 | 설정값 |
|---|---|
| 최소 노드 수 | 1 |
| 최대 노드 수 | 5 |
| 감축 | 활성 |
| 리소스 사용량 임계치 | 50 |
| 임계 영역 유지 시간 | 3 |
| 증설 후 감축 지연 시간 | 10 |
2. 파드 배포
아래의 매니페스트로 파드를 배포합니다.
[주의] 이 매니페스트처럼 컨테이너의 리소스 요청이 명시되어 있어야 합니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 15
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
resources:
requests:
cpu: "100m"
배포 요청한 파드의 CPU 리소스 총합이 노드 한 대의 리소스보다 크기 때문에 아래와 같이 몇몇 파드가 Pending 상태로 남게 됩니다. 이 상황에서 노드의 증설이 발생합니다.
# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-756fd4cdf-5gftm 1/1 Running 0 34s
nginx-deployment-756fd4cdf-64gtv 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-7bsst 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-8892p 1/1 Running 0 34s
nginx-deployment-756fd4cdf-8k4cc 1/1 Running 0 34s
nginx-deployment-756fd4cdf-cprp7 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-cvs97 1/1 Running 0 34s
nginx-deployment-756fd4cdf-h7ftk 1/1 Running 0 34s
nginx-deployment-756fd4cdf-hv2fz 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-j789l 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-jrkfj 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-m887q 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-pvnfc 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-wrj8b 1/1 Running 0 34s
nginx-deployment-756fd4cdf-x7ns5 0/1 Pending 0 34s
3. 노드 증설 확인
아래는 증설 전의 노드 목록입니다.
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
autoscaler-test-default-w-ohw5ab5wpzug-node-0 Ready <none> 45m v1.23.3
약5~10분 후 아래와 같이 노드가 증설된 것을 확인할 수 있습니다.
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
autoscaler-test-default-w-ohw5ab5wpzug-node-0 Ready <none> 48m v1.23.3
autoscaler-test-default-w-ohw5ab5wpzug-node-1 Ready <none> 77s v1.23.3
autoscaler-test-default-w-ohw5ab5wpzug-node-2 Ready <none> 78s v1.23.3
Pending 상태였던 파드가 노드 증설 이후 정상 스케줄링된 것을 확인할 수 있습니다.
# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-756fd4cdf-5gftm 1/1 Running 0 4m29s 10.100.8.13 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
nginx-deployment-756fd4cdf-64gtv 1/1 Running 0 4m29s 10.100.22.5 autoscaler-test-default-w-ohw5ab5wpzug-node-1 <none> <none>
nginx-deployment-756fd4cdf-7bsst 1/1 Running 0 4m29s 10.100.22.4 autoscaler-test-default-w-ohw5ab5wpzug-node-1 <none> <none>
nginx-deployment-756fd4cdf-8892p 1/1 Running 0 4m29s 10.100.8.10 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
nginx-deployment-756fd4cdf-8k4cc 1/1 Running 0 4m29s 10.100.8.12 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
nginx-deployment-756fd4cdf-cprp7 1/1 Running 0 4m29s 10.100.12.7 autoscaler-test-default-w-ohw5ab5wpzug-node-2 <none> <none>
nginx-deployment-756fd4cdf-cvs97 1/1 Running 0 4m29s 10.100.8.14 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
nginx-deployment-756fd4cdf-h7ftk 1/1 Running 0 4m29s 10.100.8.11 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
nginx-deployment-756fd4cdf-hv2fz 1/1 Running 0 4m29s 10.100.12.5 autoscaler-test-default-w-ohw5ab5wpzug-node-2 <none> <none>
nginx-deployment-756fd4cdf-j789l 1/1 Running 0 4m29s 10.100.22.6 autoscaler-test-default-w-ohw5ab5wpzug-node-1 <none> <none>
nginx-deployment-756fd4cdf-jrkfj 1/1 Running 0 4m29s 10.100.12.4 autoscaler-test-default-w-ohw5ab5wpzug-node-2 <none> <none>
nginx-deployment-756fd4cdf-m887q 1/1 Running 0 4m29s 10.100.22.3 autoscaler-test-default-w-ohw5ab5wpzug-node-1 <none> <none>
nginx-deployment-756fd4cdf-pvnfc 1/1 Running 0 4m29s 10.100.12.6 autoscaler-test-default-w-ohw5ab5wpzug-node-2 <none> <none>
nginx-deployment-756fd4cdf-wrj8b 1/1 Running 0 4m29s 10.100.8.15 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
nginx-deployment-756fd4cdf-x7ns5 1/1 Running 0 4m29s 10.100.12.3 autoscaler-test-default-w-ohw5ab5wpzug-node-2 <none> <none>
노드 증설에 대한 이벤트는 아래 명령어로 확인할 수 있습니다.
# kubectl get events --field-selector reason="TriggeredScaleUp"
LAST SEEN TYPE REASON OBJECT MESSAGE
4m Normal TriggeredScaleUp pod/nginx-deployment-756fd4cdf-64gtv pod triggered scale-up: [{default-worker-bf5999ab 1->3 (max: 5)}]
4m Normal TriggeredScaleUp pod/nginx-deployment-756fd4cdf-7bsst pod triggered scale-up: [{default-worker-bf5999ab 1->3 (max: 5)}]
...
4. 파드 삭제 후 노드 감축 확인
배포되어 있는 디플로이먼트(deployment)를 삭제하면 배포되어 있던 파드가 삭제됩니다.
# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-756fd4cdf-5gftm 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-64gtv 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-7bsst 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-8892p 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-8k4cc 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-cprp7 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-h7ftk 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-hv2fz 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-j789l 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-jrkfj 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-m887q 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-pvnfc 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-wrj8b 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-x7ns5 0/1 Terminating 0 20m
#
# kubectl get pods
No resources found in default namespace.
#
잠시 후 노드 감축이 발생하여 노드 수가 1개로 줄어든 것을 확인할 수 있습니다. 노드 감축에 걸리는 시간은 설정에 따라 달라질 수 있습니다.
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
autoscaler-test-default-w-ohw5ab5wpzug-node-0 Ready <none> 71m v1.23.3
노드 감축에 대한 이벤트는 아래 명령어로 확인할 수 있습니다.
# kubectl get events --field-selector reason="ScaleDown"
LAST SEEN TYPE REASON OBJECT MESSAGE
13m Normal ScaleDown node/autoscaler-test-default-w-ohw5ab5wpzug-node-1 node removed by cluster autoscaler
13m Normal ScaleDown node/autoscaler-test-default-w-ohw5ab5wpzug-node-2 node removed by cluster autoscaler
노드 그룹별 오토 스케일러의 상태 정보는 configmap/cluster-autoscaler-status를 통해 확인할 수 있습니다. 이 컨피그맵(configmap)은 노드 그룹별로 서로 다른 네임스페이스에 생성됩니다. 오토 스케일러가 생성하는 노드 그룹별 네임스페이스의 이름 규칙은 다음과 같습니다.
- 형식: nhn-ng-{노드그룹명}
- {노드그룹명}에는 노드 그룹의 이름이 들어갑니다.
- 기본 노드 그룹의 노드 그룹 이름은 "default-worker" 입니다.
기본 노드 그룹에 대한 오토 스케일러의 상태 정보를 확인하는 방법은 다음과 같습니다. 보다 자세한 정보는 Cluster Autoscaler FAQ를 참고하세요.
# kubectl get configmap/cluster-autoscaler-status -n nhn-ng-default-worker -o yaml
apiVersion: v1
data:
status: |+
Cluster-autoscaler status at 2020-11-03 12:39:12.190150095 +0000 UTC:
Cluster-wide:
Health: Healthy (ready=1 unready=0 notStarted=0 longNotStarted=0 registered=1 longUnregistered=0)
LastProbeTime: 2020-11-03 12:39:12.185954244 +0000 UTC m=+43.664545435
LastTransitionTime: 2020-11-03 12:38:41.705407217 +0000 UTC m=+13.183998415
ScaleUp: NoActivity (ready=1 registered=1)
LastProbeTime: 2020-11-03 12:39:12.185954244 +0000 UTC m=+43.664545435
LastTransitionTime: 2020-11-03 12:38:41.705407217 +0000 UTC m=+13.183998415
ScaleDown: NoCandidates (candidates=0)
LastProbeTime: 2020-11-03 12:39:12.185954244 +0000 UTC m=+43.664545435
LastTransitionTime: 2020-11-03 12:38:41.705407217 +0000 UTC m=+13.183998415
NodeGroups:
Name: default-worker-f9a9ee5e
Health: Healthy (ready=1 unready=0 notStarted=0 longNotStarted=0 registered=1 longUnregistered=0 cloudProviderTarget=1 (minSize=1, maxSize=5))
LastProbeTime: 2020-11-03 12:39:12.185954244 +0000 UTC m=+43.664545435
LastTransitionTime: 2020-11-03 12:38:41.705407217 +0000 UTC m=+13.183998415
ScaleUp: NoActivity (ready=1 cloudProviderTarget=1)
LastProbeTime: 2020-11-03 12:39:12.185954244 +0000 UTC m=+43.664545435
LastTransitionTime: 2020-11-03 12:38:41.705407217 +0000 UTC m=+13.183998415
ScaleDown: NoCandidates (candidates=0)
LastProbeTime: 2020-11-03 12:39:12.185954244 +0000 UTC m=+43.664545435
LastTransitionTime: 2020-11-03 12:38:41.705407217 +0000 UTC m=+13.183998415
kind: ConfigMap
metadata:
annotations:
cluster-autoscaler.kubernetes.io/last-updated: 2020-11-03 12:39:12.190150095 +0000
UTC
creationTimestamp: "2020-11-03T12:38:28Z"
name: cluster-autoscaler-status
namespace: nhn-ng-default-worker
resourceVersion: "1610"
selfLink: /api/v1/namespaces/nhn-ng-default-worker/configmaps/cluster-autoscaler-status
uid: e72bd1a2-a56f-41b4-92ee-d11600386558
[참고] 상태 정보의 내용 중
Cluster-wide영역의 내용은NodeGroups영역의 내용과 같습니다.
HPA(HorizontalPodAutoscale) 기능과 연동한 동작 예시
HPA(Horizontal Pod Autoscaler) 기능은 CPU 사용량 등의 리소스 사용량을 관찰하여 레플리케이션 컨트롤러(ReplicationController), 디플로이먼트(Deployment), 레플리카셋(ReplicaSet), 스테이트풀셋(StatefulSet)의 파드 개수를 자동으로 스케일합니다. 파드 개수를 조절하다 보면 노드에 가용 리소스가 부족하거나 리소스가 많이 남는 상황이 발생할 수 있습니다. 이때 오토 스케일러 기능과 연동하여 노드의 수를 늘이거나 줄일 수 있습니다. 이 예제에서는 HPA 기능과 오토 스케일러 기능을 연동해 동작하는 것을 보여줍니다. HPA에 대한 자세한 설명은 Horizontal Pod Autoscaler 문서를 참고하세요.
1. 오토 스케일러 활성화
위의 예제와 같이 오토 스케일러를 활성화 합니다.
2. HPA 설정
웹 요청을 받으면 일정 시간동안 CPU 부하를 생성하는 컨테이너를 배포합니다. 그리고 서비스를 노출시킵니다. 다음은 php-apache.yaml 파일의 내용입니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: k8s.gcr.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
# kubectl apply -f php-apache.yaml
deployment.apps/php-apache created
service/php-apache created
이제 HPA를 설정합니다. 위에서 방금 생성한 php-apache deployment 객체에 대해 최소 파드 수 1, 최대 파드 수 30, 목표 CPU load는 50%로 설정합니다.
# kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=30
horizontalpodautoscaler.autoscaling/php-apache autoscaled
HPA의 상태를 조회해보면 설정값과 현재 상태를 볼 수 있습니다. 아직 CPU 부하를 일으키는 web request를 보내지 않았기 때문에 CPU load가 0% 입니다.
# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 30 1 80s
3. 부하 인가
이제 새로운 터미널에서 부하를 일으키는 파드를 실행합니다. 이 파드는 무한히 웹 요청을 보내게 됩니다. Ctrl+C로 멈출 수 있습니다.
# kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
If you don't see a command prompt, try pressing enter.
OK!OK!OK!OK!OK!OK!OK!
kubectl top nodes 커맨드를 이용해 노드의 현재 리소스 사용량을 확인할 수 있습니다. 부하를 일으키는 파드 실행 후 시간이 흐르면서 CPU 부하가 커지는 것을 확인할 수 있습니다.
# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
autoscaler-test-default-w-ohw5ab5wpzug-node-0 66m 6% 1010Mi 58%
(잠시 후)
# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
autoscaler-test-default-w-ohw5ab5wpzug-node-0 574m 57% 1013Mi 58%
HPA의 상태를 조회해보면 CPU load가 증가했고, 이를 맞추기 위해 REPLICAS(=파드 수)가 수가 늘어난 것을 확인할 수 있습니다.
# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 250%/50% 1 30 5 2m44s
4. 오토 스케일러 동작 확인
파드를 조회해보면 파드의 수가 늘어나면서 일부 파드는 node-0에 스케줄링되어 Running 상태가 됐지만 일부는 Pending 상태인 것을 확인할 수 있습니다
# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
load-generator 1/1 Running 0 2m 10.100.8.39 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
php-apache-79544c9bd9-6f7nm 0/1 Pending 0 65s <none> <none> <none> <none>
php-apache-79544c9bd9-82xkn 1/1 Running 0 80s 10.100.8.41 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
php-apache-79544c9bd9-cjj9q 0/1 Pending 0 80s <none> <none> <none> <none>
php-apache-79544c9bd9-k6nnt 1/1 Running 0 4m27s 10.100.8.38 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
php-apache-79544c9bd9-mplnn 0/1 Pending 0 19s <none> <none> <none> <none>
php-apache-79544c9bd9-t2knw 1/1 Running 0 80s 10.100.8.40 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
파드를 스케줄링하지 못하는 상황이 바로 오토 스케일러의 노드 증설 조건입니다. Cluster Autoscaler 파드가 제공하는 상태 정보를 조회해보면 ScaleUp이 InProgress 상태가 된 것을 확인할 수 있습니다.
# kubectl get cm/cluster-autoscaler-status -n nhn-ng-default-worker -o yaml
apiVersion: v1
data:
status: |+
Cluster-autoscaler status at 2020-11-24 13:00:40.210137143 +0000 UTC:
Cluster-wide:
Health: Healthy (ready=1 unready=0 notStarted=0 longNotStarted=0 registered=1 longUnregistered=0)
LastProbeTime: 2020-11-24 13:00:39.930763305 +0000 UTC m=+1246178.729396969
LastTransitionTime: 2020-11-10 02:51:14.353177175 +0000 UTC m=+13.151810823
ScaleUp: InProgress (ready=1 registered=1)
LastProbeTime: 2020-11-24 13:00:39.930763305 +0000 UTC m=+1246178.729396969
LastTransitionTime: 2020-11-24 12:58:34.83642035 +0000 UTC m=+1246053.635054003
ScaleDown: NoCandidates (candidates=0)
LastProbeTime: 2020-11-24 13:00:39.930763305 +0000 UTC m=+1246178.729396969
LastTransitionTime: 2020-11-20 01:42:32.287146552 +0000 UTC m=+859891.085780205
NodeGroups:
Name: default-worker-bf5999ab
Health: Healthy (ready=1 unready=0 notStarted=0 longNotStarted=0 registered=1 longUnregistered=0 cloudProviderTarget=2 (minSize=1, maxSize=3))
LastProbeTime: 2020-11-24 13:00:39.930763305 +0000 UTC m=+1246178.729396969
LastTransitionTime: 2020-11-10 02:51:14.353177175 +0000 UTC m=+13.151810823
ScaleUp: InProgress (ready=1 cloudProviderTarget=2)
LastProbeTime: 2020-11-24 13:00:39.930763305 +0000 UTC m=+1246178.729396969
LastTransitionTime: 2020-11-24 12:58:34.83642035 +0000 UTC m=+1246053.635054003
ScaleDown: NoCandidates (candidates=0)
LastProbeTime: 2020-11-24 13:00:39.930763305 +0000 UTC m=+1246178.729396969
LastTransitionTime: 2020-11-20 01:42:32.287146552 +0000 UTC m=+859891.085780205
...
잠시 후 노드(node-8)가 하나 늘어난 것을 확인할 수 있습니다.
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
autoscaler-test-default-w-ohw5ab5wpzug-node-0 Ready <none> 22d v1.23.3
autoscaler-test-default-w-ohw5ab5wpzug-node-8 Ready <none> 90s v1.23.3
Pending 상태였던 파드 모두 정상 스케줄링되어 Running 상태가 된 것을 확인할 수 있습니다.
# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
load-generator 1/1 Running 0 5m32s 10.100.8.39 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
php-apache-79544c9bd9-6f7nm 1/1 Running 0 4m37s 10.100.42.3 autoscaler-test-default-w-ohw5ab5wpzug-node-8 <none> <none>
php-apache-79544c9bd9-82xkn 1/1 Running 0 4m52s 10.100.8.41 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
php-apache-79544c9bd9-cjj9q 1/1 Running 0 4m52s 10.100.42.5 autoscaler-test-default-w-ohw5ab5wpzug-node-8 <none> <none>
php-apache-79544c9bd9-k6nnt 1/1 Running 0 7m59s 10.100.8.38 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
php-apache-79544c9bd9-mplnn 1/1 Running 0 3m51s 10.100.42.4 autoscaler-test-default-w-ohw5ab5wpzug-node-8 <none> <none>
php-apache-79544c9bd9-t2knw 1/1 Running 0 4m52s 10.100.8.40 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
부하를 위해 실행해두었던 파드(load-generator)를 Ctrl+C로 중단시키면 잠시 후 부하가 줄어들게 됩니다. 부하가 줄면 파드가 점유하던 CPU 사용량이 줄어들어 파드의 수가 줄어들게 됩니다.
# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 30 1 31m
파드의 수가 줄어들어 노드의 리소스 사용량이 줄어들면 결국 노드 감축이 발생합니다. 새로 추가되었던 node-8이 감축된 것을 확인할 수 있습니다.
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
autoscaler-test-default-w-ohw5ab5wpzug-node-0 Ready <none> 22d v1.23.3
사용자 스크립트(old)
클러스터를 생성할 때와 추가 노드 그룹을 생성할 때, 사용자 스크립트를 등록할 수 있습니다. 사용자 스크립트 기능에는 다음과 같은 특징이 있습니다.
- 기능 설정
- 이 기능은 워커 노드 그룹별로 설정할 수 있습니다.
- 클러스터 생성 시 입력한 사용자 스크립트는 기본 워커 노드 그룹에 적용됩니다.
- 추가 노드 그룹 생성 시 입력한 사용자 스크립트는 해당 워커 노드 그룹에 적용됩니다.
- 워커 노드 그룹이 생성된 후에는 사용자 스크립트의 내용을 변경할 수 없습니다.
- 스크립트 실행 시점
- 사용자 스크립트는 워커 노드 초기화 과정 중 인스턴스 초기화 과정에서 실행됩니다.
- 사용자 스크립트가 실행된 후, 해당 인스턴스를 '워커 노드 그룹'의 워커 노드로 설정하고 등록합니다.
- 스크립트 내용
- 사용자 스크립트의 첫번째 줄은 반드시 #! 으로 시작해야 합니다.
- 스크립트 최대 크기는 64KB입니다.
- 스크립트는 root 권한으로 실행됩니다.
- 스크립트 실행 기록은 아래 위치에 저장됩니다.
- 스크립트 종료 코드:
/var/log/userscript.exitcode - 스크립트 표준 출력 및 표준 에러 스트림:
/var/log/userscript.output
- 스크립트 종료 코드:
사용자 스크립트
2022년 7월 26일 이후에 생성되는 노드 그룹에는 새로운 버전의 사용자 스크립트 기능이 탑재됩니다. 이전 버전의 기능에 비해 다음과 같은 특징이 있습니다.
- 워커 노드 그룹이 생성된 후에도 사용자 스크립트의 내용을 변경할 수 있습니다.
- 단, 변경된 내용은 사용자 스크립트 변경 이후 생성되는 노드에만 적용됩니다.
-
스크립트 실행 기록은 아래 위치에 저장됩니다.
- 스크립트 종료 코드:
/var/log/userscript_v2.exitcode - 스크립트 표준 출력 및 표준 에러 스트림:
/var/log/userscript_v2.output
- 스크립트 종료 코드:
-
이전 버전과의 관계
- 신규 버전의 기능이 이전 버전의 기능을 대체합니다.
- 콘솔, API를 통해 노드 그룹을 생성할 때 설정한 사용자 스크립트는 신규 버전 기능으로 설정됩니다.
- 이전 버전의 사용자 스크립트를 설정한 워커 노드 그룹은 이전 버전 기능과 신규 버전 기능이 개별적으로 동작합니다.
- 이전 버전에 설정한 사용자 스크립트의 내용은 변경할 수 없습니다.
- 신규 버전에 설정한 사용자 스크립트의 내용은 변경할 수 있습니다.
- 이전 버전과 신규 버전에 각각 사용자 스크립트를 설정하면 다음의 순서로 실행됩니다.
- 이전 버전의 사용자 스크립트
- 신규 버전의 사용자 스크립트
- 신규 버전의 기능이 이전 버전의 기능을 대체합니다.
인스턴스 타입 변경
워커 노드 그룹의 인스턴스 타입을 변경합니다. 워커 노드 그룹에 속한 모든 워커 노드의 인스턴스 타입이 변경됩니다.
진행 과정
인스턴스 타입 변경은 다음 순서로 진행됩니다.
- 클러스터 오토스케일러 기능을 비활성화합니다.
- 해당 워커 노드 그룹에 버퍼 노드를 추가합니다.
- 워커 노드 그룹 내의 모든 워커 노드에 대해 순차적으로 아래 작업을 수행합니다.
- 해당 워커 노드에서 동작 중인 파드를 축출하고, 노드를 스케줄 불가능한 상태로 전환합니다.
- 워커 노드의 인스턴스 타입을 변경합니다.
- 노드를 스케줄 가능한 상태로 전환합니다.
- 버퍼 노드에서 동작 중인 파드를 축출하고 버퍼 노드를 삭제합니다.
- 클러스터 오토스케일러 기능을 다시 활성화합니다.
인스턴스 타입 변경은 워커 구성 요소 업그레이드와 유사한 방법으로 진행됩니다. 버퍼 노드의 생성과 삭제, 파드의 축출에 대해서는 클러스터 업그레이드를 참고하세요.
제약 사항
인스턴스의 현재 타입에 따라 변경할 수 있는 타입이 다릅니다.
- m2, c2, r2, t2, x1 타입의 인스턴스는 m2, c2, r2, t2, x1 타입으로 변경할 수 있습니다.
- m2, c2, r2, t2, x1, g2 타입의 인스턴스는 u2 타입으로 변경할 수 없습니다.
- u2 타입의 인스턴스는 생성 이후에 타입을 변경할 수 없습니다. 같은 u2 타입으로의 변경도 불가합니다.
커스텀 이미지를 워커 이미지로 활용
사용자의 커스텀 이미지를 기반으로 한 워커 노드 그룹을 생성할 수 있습니다. 커스텀 이미지가 워커 노드 이미지로 활용될 수 있도록 NHN Cloud Image Builder 서비스에서 추가적인 작업(NKS 워커 노드화)이 필요합니다. Image Builder 서비스에서 NHN Kubernetes Service(NKS) 워커 노드 애플리케이션으로 이미지 템플릿을 생성하여 커스텀 워커 노드 이미지를 생성할 수 있습니다. Image Builder 서비스에 대한 자세한 내용은 Image Builder 사용자 가이드를 참고하세요.
[주의] NKS 워커 노드화 작업에는 패키지 설치 및 설정 변경 등이 포함되어 있어 정상적으로 동작하지 않는 이미지로 작업을 진행하는 경우 실패할 수 있습니다. Image Builder 서비스 사용에 대해 과금될 수 있습니다.
제약 사항
NHN Cloud 인스턴스를 기반으로 생성한 커스텀 이미지만 워커 노드 이미지로 사용할 수 있습니다. 해당 기능은 특정 인스턴스 이미지에 대해서만 제공됩니다. 커스텀 이미지를 생성하는 기반 인스턴스의 이미지에 맞춰 올바른 버전의 워커 노드화 애플리케이션을 선택해야 합니다. 인스턴스 이미지별 선택해야 하는 애플리케이션 버전 정보는 아래 표를 참고하세요.
| OS | 이미지 | 애플리케이션 버전 |
|---|---|---|
| CentOS | CentOS 7.9 (2022.11.22) | 1.0 |
| CentOS 7.9 (2023.05.25) | 1.1 | |
| CentOS 7.9 (2023.08.22) | 1.2 | |
| CentOS 7.9 (2023.11.21) | 1.3 | |
| CentOS 7.9 (2024.02.20) | 1.4 | |
| Rocky | Rocky Linux 8.6 (2023.03.21) | 1.0 |
| Rocky Linux 8.7 (2023.05.25) | 1.1 | |
| Rocky Linux 8.8 (2023.08.22) | 1.2 | |
| Rocky Linux 8.8 (2023.11.21) | 1.3 | |
| Rocky Linux 8.9 (2024.02.20) | 1.4 | |
| Ubuntu | Ubuntu Server 18.04.6 LTS (2023.03.21) | 1.0 |
| Ubuntu Server 20.04.6 LTS (2023.05.25) | 1.1 | |
| Ubuntu Server 20.04.6 LTS (2023.08.22) | 1.2 | |
| Ubuntu Server 20.04.6 LTS (2023.11.21) | 1.3 | |
| Ubuntu Server 22.04.3 LTS (2023.11.21) | 1.3 | |
| Ubuntu Server 20.04.6 LTS (2024.02.20) | 1.4 | |
| Ubuntu Server 22.04.3 LTS (2024.02.20) | 1.4 | |
| Debian | Debian 11.6 Bullseye (2023.03.21) | 1.0 |
| Debian 11.6 Bullseye (2023.05.25) | 1.1 | |
| Debian 11.7 Bullseye (2023.08.22) | 1.2 | |
| Debian 11.8 Bullseye (2023.11.21) | 1.3 | |
| Debian 11.8 Bullseye (2024.02.20) | 1.4 |
[참고] 커스텀 이미지를 워커 노드 이미지로 변환하는 과정에서 선택한 옵션에 따라 GPU 드라이버가 설치됩니다. 따라서 커스텀 GPU 워커 노드 이미지를 생성하는 경우에도 커스텀 이미지 생성을 GPU 인스턴스로 할 필요가 없습니다.
진행 과정
커스텀 이미지를 워커 노드 이미지로 활용하기 위해서 Image Builder 서비스에서 아래와 같은 과정을 수행합니다.
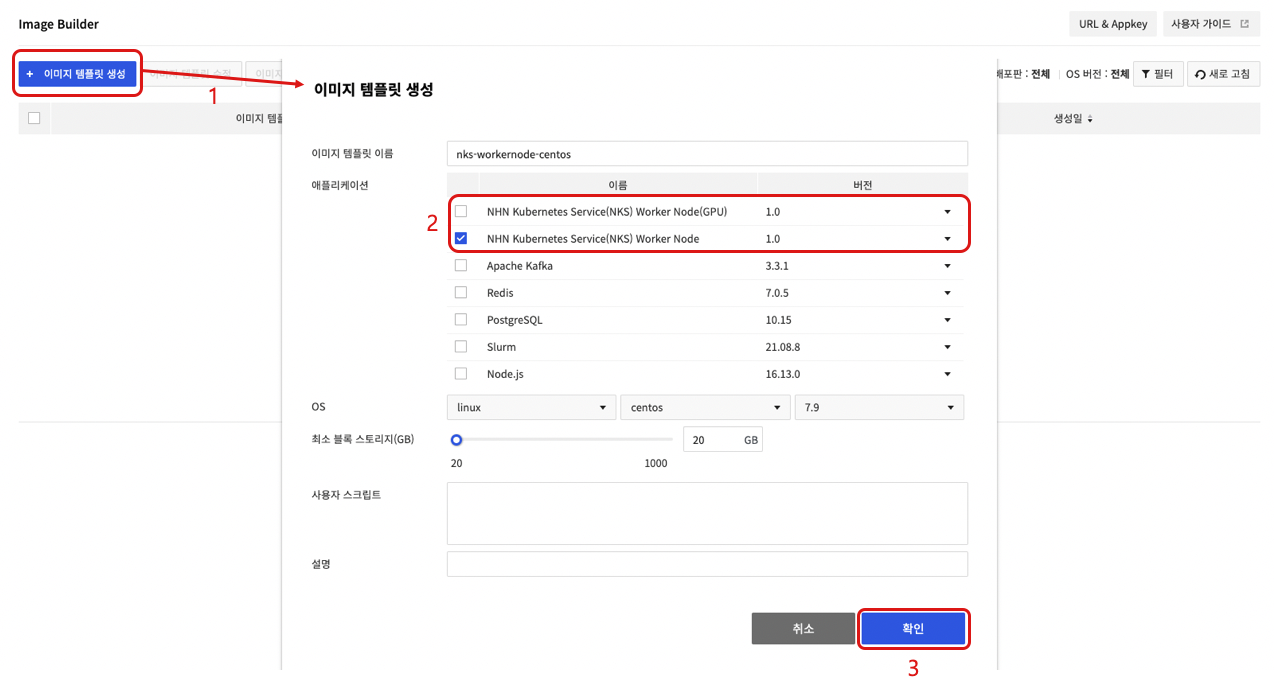
- 이미지 템플릿을 생성을 클릭합니다.
- 애플리케이션을 선택한 후 이미지 템플릿 이름, OS, 최소 블록 스토리지(GB), 사용자 스크립트, 설명을 작성합니다.
- GPU Flavor를 사용하지 않는 워커 노드 그룹인 경우 NHN Kubernetes Service(NKS) Worker Node 애플리케이션을 선택합니다.
- GPU Flavor를 사용하는 워커 노드 그룹인 경우 NHN Kubernetes Service(NKS) Worker Node(GPU) 애플리케이션을 선택합니다.
- 확인을 클릭해 이미지 템플릿을 생성합니다.
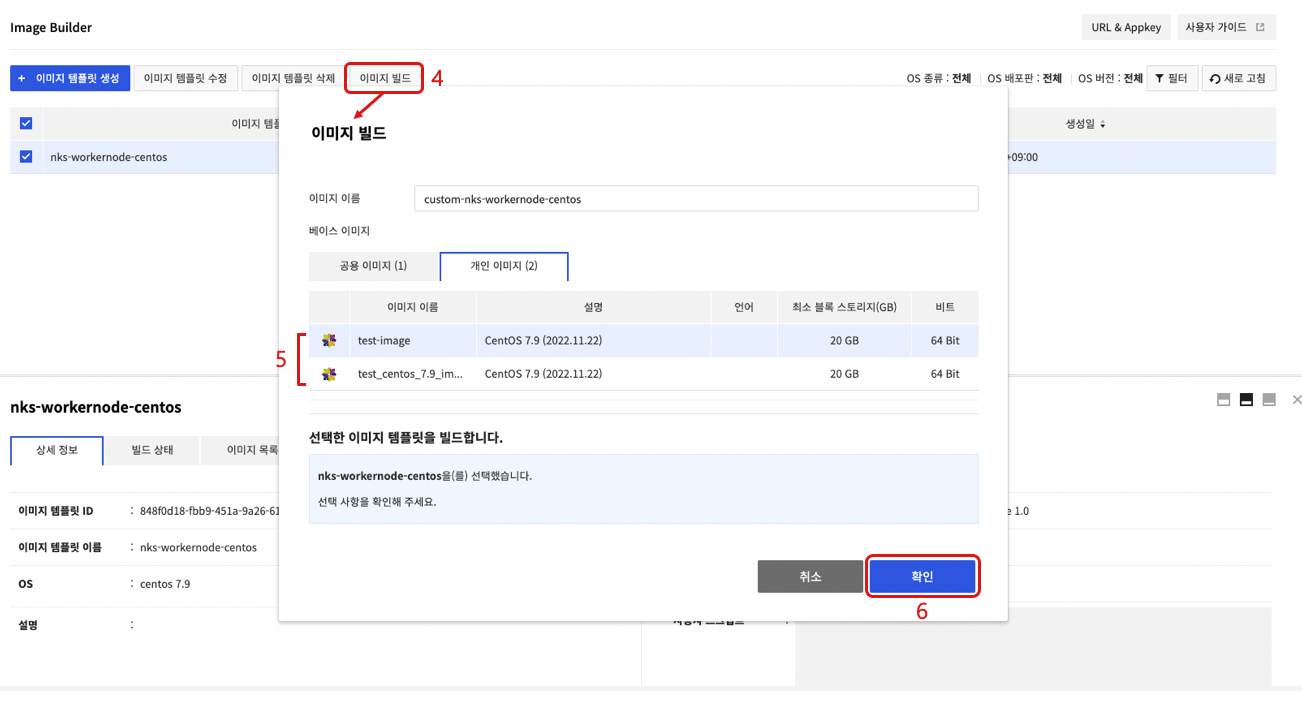
- 생성된 이미지 템플릿을 선택한 후 이미지 빌드를 선택합니다.
- 이미지 빌드 화면에서 개인 이미지 탭을 선택한 뒤 NKS 워커 노드화를 진행할 커스텀 이미지를 선택합니다.
- 확인을 클릭하면 NKS 워커 노드화가 진행된 후 새로운 이미지를 생성합니다.
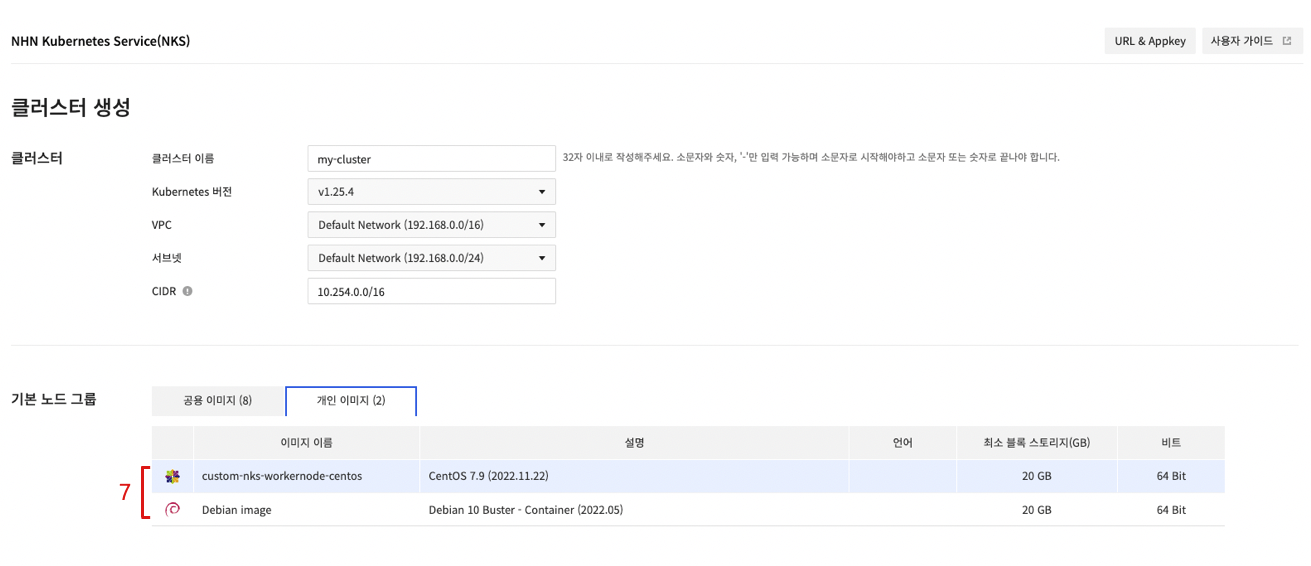
- 클러스터 생성 화면 또는 노드 그룹 생성 화면에서 생성된 커스텀 이미지를 선택합니다.
클러스터 관리
원격의 호스트에서 클러스터를 조작하고 관리하려면 Kubernetes가 제공하는 명령줄 도구(CLI)인 kubectl이 필요합니다.
kubectl 설치
kubectl은 특별한 설치 과정 없이 실행 파일을 다운로드해 바로 사용할 수 있습니다. 운영체제별 다운로드 경로는 다음과 같습니다.
[주의] 워커 노드에서 패키지 매니저를 이용해 kubeadm, kubelet, kubectl 등의 Kubernetes 관련 컴포넌트를 설치하면 클러스터의 오동작을 일으킬 수 있습니다. 워커 노드에 kubectl을 설치하는 경우 아래 다운로드 커맨드를 참고해 파일을 다운로드하시길 바랍니다.
| 운영체제 | 다운로드 커맨드 |
|---|---|
| Linux | curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.15.7/bin/linux/amd64/kubectl |
| MacOS | curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.15.7/bin/darwin/amd64/kubectl |
| Windows | curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.15.7/bin/windows/amd64/kubectl.exe |
그 외 설치 방법과 옵션 등 자세한 사항은 Install and Set Up kubectl 문서를 참고하세요.
권한 변경
다운로드한 파일은 기본적으로 실행 권한이 없습니다. 실행 권한을 추가해야 합니다.
$ chmod +x kubectl
위치 변경 또는 경로 지정
어느 경로에서든 kubectl을 실행할 수 있도록 환경 변수에 지정된 경로로 옮기거나, kubectl이 있는 경로를 환경 변수에 추가합니다.
- 환경 변수에 지정된 경로로 위치 변경
$ sudo mv kubectl /usr/local/bin/
- 환경 변수에 경로 추가
// kubectl이 있는 경로에서 실행
$ export PATH=$PATH:$(pwd)
설정
kubectl로 Kubernetes 클러스터에 접근하려면 클러스터 설정 파일(kubeconfig)이 필요합니다. NHN Cloud 웹 콘솔에서 Container > NHN Kubernetes Service(NKS) 페이지를 열고 접근할 클러스터를 선택합니다. 하단 기본 정보 탭에서 설정 파일 항목의 다운로드 버튼을 클릭해 설정 파일을 다운로드합니다. 다운로드한 설정 파일은 원하는 위치로 옮겨 kubectl 실행 시 참조할 수 있도록 준비합니다.
[주의] NHN Cloud 웹 콘솔에서 다운로드한 설정 파일은 클러스터 정보와 인증을 위한 토큰 등이 포함되어 있습니다. 설정 파일이 있으면 해당 Kubernetes 클러스터에 접근할 수 있는 권한을 갖게 됩니다. 설정 파일을 절대로 분실하지 않도록 주의하시기 바랍니다.
kubectl은 실행할 때마다 클러스터 설정 파일이 필요합니다. 따라서 매번 --kubeconfig 옵션을 이용해 클러스터 설정 파일을 지정해야 합니다. 그러나 환경 변수에 클러스터 설정 파일 경로가 저장되어 있다면 매번 옵션을 지정하지 않아도 됩니다.
$ export KUBECONFIG={클러스터 설정 파일 경로}
클러스터 설정 파일 경로를 환경 변수에 저장하고 싶지 않다면 kubectl의 기본 설정 파일인 $HOME/.kube/config로 복사해 사용할 수도 있습니다. 그러나 클러스터를 여러 개 운영한다면 환경 변숫값을 변경하는 방법이 편리합니다.
연결 확인
kubectl version 명령어로 정상 설정되었는지 확인합니다. 문제가 없다면 Server Version이 출력됩니다.
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"15", GitVersion:"v1.15.7", GitCommit:"6c143d35bb11d74970e7bc0b6c45b6bfdffc0bd4", GitTreeState:"clean", BuildDate:"2019-12-11T12:42:56Z", GoVersion:"go1.12.12", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"15", GitVersion:"v1.15.7", GitCommit:"6c143d35bb11d74970e7bc0b6c45b6bfdffc0bd4", GitTreeState:"clean", BuildDate:"2019-12-11T12:34:17Z", GoVersion:"go1.12.12", Compiler:"gc", Platform:"linux/amd64"}
- Client Version: 실행한 kubectl 파일의 버전 정보
- Server Version: 클러스터를 구성하고 있는 Kubernetes 버전 정보
CSR(CertificateSigningRequest)
Kubernetes의 인증 API(Certificate API)를 통해 Kubernetes API 클라이언트를 위한 X.509 인증서(certificate)를 요청하고 발급할 수 있습니다. CSR 자원은 인증서를 요청하고, 요청에 대해 승인/거부를 결정할 수 있도록 합니다. 자세한 사항은 Certificate Signing Requests 문서를 참고하세요.
CSR 요청과 발급 승인 예제
먼저 개인 키(private key)를 생성합니다. 인증서 생성에 관한 자세한 내용은 Certificates 문서를 참고하세요.
$ openssl genrsa -out dev-user1.key 2048
Generating RSA private key, 2048 bit long modulus
...........................................................................+++++
..................+++++
e is 65537 (0x010001)
$ openssl req -new -key dev-user1.key -subj "/CN=dev-user1" -out dev-user1.csr
생성한 개인 키 정보를 포함하는 CSR 자원을 생성해 인증서 발급을 요청합니다.
$ BASE64_CSR=$(cat dev-user1.csr | base64 | tr -d '\n')
$ cat <<EOF > csr.yaml -
apiVersion: certificates.k8s.io/v1
kind: CertificateSigningRequest
metadata:
name: dev-user1
spec:
groups:
- system:authenticated
request: ${BASE64_CSR}
signerName: kubernetes.io/kube-apiserver-client
expirationSeconds: 86400 # one day
usages:
- client auth
EOF
$ kubectl apply -f csr.yaml
certificatesigningrequest.certificates.k8s.io/dev-user1 created
등록된 CSR은 Pending 상태입니다. 이 상태는 발급 승인 또는 거부를 기다리는 상태입니다.
$ kubectl get csr
NAME AGE SIGNERNAME REQUESTOR REQUESTEDDURATION CONDITION
dev-user1 3s kubernetes.io/kube-apiserver-client admin 24h Pending
이 인증서 발급 요청에 대해 승인 처리합니다.
$ kubectl certificate approve dev-user1
certificatesigningrequest.certificates.k8s.io/dev-user1 approved
CSR을 다시 확인해보면 Approved,Issued 상태로 변경된 것을 확인할 수 있습니다.
$ kubectl get csr
NAME AGE SIGNERNAME REQUESTOR REQUESTEDDURATION CONDITION
dev-user1 28s kubernetes.io/kube-apiserver-client admin 24h Approved,Issued
인증서는 다음과 같이 조회할 수 있습니다. 인증서는 status의 certificate 필드의 값입니다.
$ apiVersion: certificates.k8s.io/v1
kind: CertificateSigningRequest
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"certificates.k8s.io/v1","kind":"CertificateSigningRequest","metadata":{"annotations":{},"name":"dev-user1"},"spec":{"expirationSeconds":86400,"groups":["system:authenticated"],"request":"LS0t..(이하생략)","signerName":"kubernetes.io/kube-apiserver-client","usages":["client auth"]}}
creationTimestamp: "2023-09-15T05:53:12Z"
name: dev-user1
resourceVersion: "176619"
uid: a5813153-40de-4725-9237-3bf684fd1db9
spec:
expirationSeconds: 86400
groups:
- system:masters
- system:authenticated
request: LS0t..(이하생략)
signerName: kubernetes.io/kube-apiserver-client
usages:
- client auth
username: admin
status:
certificate: LS0t..(이하생략)
conditions:
- lastTransitionTime: "2023-09-15T05:53:26Z"
lastUpdateTime: "2023-09-15T05:53:26Z"
message: This CSR was approved by kubectl certificate approve.
reason: KubectlApprove
status: "True"
type: Approved
승인 컨트롤러(admission controller) 플러그인
승인 컨트롤러는 Kubernetes API 서버 요청을 가로채 객체를 변경하거나 요청을 거부할 수 있습니다. 승인 컨트롤러에 대한 자세한 설명은 승인 컨트롤러를 참고하세요. 그리고 승인 컨트롤러의 사용 예제는 승인 컨트롤러 가이드를 참고하세요.
클러스터 버전과 클러스터 생성 시점에 따라 승인 컨트롤러에 적용되는 플러그인의 종류가 다릅니다. 자세한 내용은 리전별 생성 시점에 따른 플러그인 목록을 참고하세요.
- DefaultStorageClass
- DefaultTolerationSeconds
- LimitRanger
- MutatingAdmissionWebhook
- NamespaceLifecycle
- NodeRestriction
- PodSecurityPolicy(신규 추가)
- ResourceQuota
- ServiceAccount
- ValidatingAdmissionWebhook
v1.20.12 이후 버전
Kubernetes 버전 별 기본 활성 승인 컨트롤러는 모두 활성화됩니다. 기본 활성 승인 컨트롤러에 아래의 컨트롤러가 추가 활성화됩니다.
- NodeRestriction
- PodSecurityPolicy
클러스터 업그레이드
NHN Kubernetes Service(NKS)는 동작 중인 Kubernetes 클러스터의 Kubernetes 구성 요소 업그레이드를 지원합니다.
Kubernetes 버전 차이 지원 정책
Kubernetes 버전은 x.y.z로 표현됩니다. x는 메이저 버전, y는 마이너 버전, z는 패치 버전입니다. 기능이 추가되면 메이저 버전 혹은 마이너 버전을 올리고, 버그 수정과 같이 이전 버전과 호환되는 기능을 제공하면 패치 버전을 올립니다. 좀 더 자세한 내용은 Semantic Versioning 2.0.0을 참고하세요.
Kubernetes 클러스터는 동작 중인 상태에서 Kubernetes 구성 요소를 업그레이드할 수 있습니다. 이를 위해 Kubernetes 구성 요소별로 Kubernetes 버전 차이에 따른 기능 지원 여부를 정의하고 있습니다. 마이너 버전을 기준으로 한 단계의 버전 차이는 상호 기능 호환을 지원함으로써 동작 중인 클러스터의 Kubernetes 구성 요소 업그레이드를 지원합니다. 또 구성 요소 종류 별로 업그레이드 순서를 정의하고 있습니다. 좀 더 자세한 내용은 Version Skew Policy를 참고하세요.
기능 동작 방식
NHN Cloud에서 지원하는 Kubernetes 클러스터 업그레이드 기능의 동작 방식에 대해 설명합니다.
Kubernetes 버전 관리
NHN Cloud의 Kubernetes 클러스터는 클러스터 마스터와 워커 노드 그룹별로 Kubernetes 버전을 관리합니다. 마스터의 Kubernetes 버전은 클러스터 조회 화면에서 확인할 수 있고, 워커 노드 그룹의 Kubernetes 버전은 각 워커 노드 그룹 조회 화면에서 확인할 수 있습니다.
업그레이드 규칙
NHN Cloud의 Kubernetes 클러스터 버전 관리 방식과 Kubernetes 버전 차이 지원 정책에 의해 구성 요소별로 순서에 맞게 업그레이드해야 합니다. NHN Cloud의 Kubernetes 클러스터 업그레이드 기능에 적용되는 규칙은 다음과 같습니다.
- 마스터와 각 워커 노드 그룹별로 업그레이드 명령을 실행해야 합니다.
- 마스터의 Kubernetes 버전과 모든 워커 노드 그룹의 Kubernetes 버전이 일치해야 업그레이드가 가능합니다.
- 마스터를 먼저 업그레이드한 후 워커 노드 그룹을 업그레이드할 수 있습니다.
- 현재 버전의 다음 버전(마이너 버전 기준 +1)으로 업그레이드 가능합니다.
- 다운그레이드는 지원하지 않습니다.
- 다른 기능의 동작으로 인해 클러스터가 업데이트 중인 상태에서는 업그레이드가 불가능합니다.
- 클러스터 버전을 v1.25.4에서 v1.26.3으로 업그레이드할 때, CNI가 Flannel인 경우 Calico로 변경해야 합니다.
다음 예시는 Kubernetes 버전을 업그레이드 과정에서 업그레이드 가능 여부를 표로 나타낸 것입니다. 예시에 사용된 조건은 다음과 같습니다.
- NHN Cloud가 지원하는 Kubernetes 버전 목록: v1.21.6, v1.22.3, v1.23.3
- 클러스터는 v1.21.6으로 생성
| 상태 | 마스터 버전 | 마스터 업그레이드 가능 여부 | 워커 노드 그룹 버전 | 워커 노드 그룹 업그레이드 가능 여부 |
|---|---|---|---|---|
| 초기 상태 | v1.21.6 | 가능 1 | v1.21.6 | 불가능 2 |
| 마스터 업그레이드 후 상태 | v1.22.3 | 불가능 3 | v1.21.6 | 가능 4 |
| 워커 노드 그룹 업그레이드 후 상태 | v1.22.3 | 가능 1 | v1.22.3 | 불가능 2 |
| 마스터 업그레이드 후 상태 | v1.23.3 | 불가능 3 | v1.22.3 | 가능 4 |
| 워커 노드 그룹 업그레이드 후 상태 | v1.23.3 | 불가능 5 | v1.23.3 | 불가능 2 |
주석
- 1: 마스터와 모든 워커 노드 그룹의 버전이 일치하는 상태이기 때문에 업그레이드 가능
- 2: 워커 노드 그룹은 마스터가 업그레이드된 후 업그레이드 가능
- 3: 마스터와 모든 워커 노드 그룹의 버전이 일치해야 업그레이드 가능
- 4: 마스터가 업그레이드됐기 때문에 업그레이드 가능
- 5: NHN Cloud에서 지원하는 가장 최신 버전을 사용하고 있기 때문에 업그레이드 불가능
마스터 구성 요소 업그레이드
NHN Cloud의 Kubernetes 클러스터 마스터는 고가용성 보장을 위해 다수의 마스터로 구성되어 있습니다. 마스터에 대해 롤링 업데이트 방식으로 업그레이드되기 때문에 클러스터의 가용성이 보장됩니다.
이 과정에서 아래와 같은 일들이 발생할 수 있습니다.
- Kubernetes API가 일시적으로 실패할 수 있습니다.
워커 구성 요소 업그레이드
워커 노드 그룹별로 워커 구성 요소를 업그레이드할 수 있습니다. 워커 구성 요소 업그레이드는 다음 순서로 진행됩니다.
- 클러스터 오토스케일러 기능을 비활성화 합니다.1
- 해당 워커 노드 그룹에 버퍼 노드2를 추가합니다.3
- 워커 노드 그룹 내의 모든 워커 노드에 대해 순차적으로 아래 작업을 수행합니다.4
- 해당 워커 노드에서 동작 중인 파드를 축출하고, 노드를 스케줄 불가능한 상태로 전환합니다.
- 워커 구성 요소를 업그레이드합니다.
- 노드를 스케줄 가능한 상태로 전환합니다.
- 버퍼 노드에서 동작 중인 파드를 축출하고 버퍼 노드를 삭제합니다.
- 클러스터 오토스케일러 기능을 다시 활성화 합니다.1
주석
- 1: 이 단계는 업그레이드 기능 시작 전 클러스터 오토스케일러 기능이 활성화 되어 있는 경우에만 유효합니다.
- 2: 버퍼 노드란 업그레이드 과정 중 기존 워커 노드에서 축출당한 파드가 다시 스케줄링 가능하도록 생성해놓는 여유 노드를 말합니다. 해당 워커 노드 그룹에서 정의한 워커 노드와 동일한 규격의 노드로 생성되며, 업그레이드 과정이 종료될 때 자동으로 삭제됩니다. 이 노드는 Instance 요금 정책에 따라 비용이 청구됩니다.
- 3: 업그레이드 시 버퍼 노드 수를 설정할 수 있습니다. 기본값은 1이며, 0으로 설정하면 버퍼 노드를 추가하지 않습니다. 최솟값은 0이고, 최댓값은 (노드 그룹당 최대 노드 수 쿼터-해당 워커 노드 그룹의 현재 노드 수)입니다.
- 4: 업그레이드 시 설정한 최대 서비스 불가 노드 수만큼씩 작업을 수행합니다. 기본값은 1입니다. 최솟값은 1이고, 최댓값은 해당 워커 노드 그룹의 현재 노드 수입니다.
이 과정에서 아래와 같은 일들이 발생할 수 있습니다.
- 서비스 중인 파드가 축출되어 다른 노드로 스케줄링 됩니다(파드 축출에 대한 더 자세한 내용은 아래 파드 축출 관련 유의 사항을 참고하시길 바랍니다).
- 오토스케일러 기능이 동작하지 않습니다.
[파드 축출 관련 유의 사항] 1. 데몬셋(daemonset) 컨트롤러에 의한 파드는 축출되지 않습니다. 데몬셋 컨트롤러는 각 워커 노드 별로 파드를 실행하기 떄문에 데몬셋 컨트롤러에 의해 실행된 파드는 축출되더라도 다른 노드에서 실행될 수 없습니다. 워커 노드 그룹 업그레이드 과정에서 데몬셋 컨트롤러에 의해 실행된 파드는 축출하지 않습니다. 2. 로컬 저장 공간을 사용하는 파드는 축출되면서 사용하던 데이터를 잃게 됩니다.
emptyDir을 이용해 노드의 로컬 저장 공간을 사용하는 파드는 축출되면서 사용하던 데이터를 잃게 됩니다. 노드의 로컬에 저장된 저장 공간이 다른 노드로 옮겨갈 수 없기 때문입니다. 3. 다른 노드로 복제가 불가능한 파드는 다른 노드로 옮겨지지 않습니다. 리플리케이션 컨트롤러(ReplicationController), 레플리카셋(ReplicaSet), 잡(Job), 데몬셋(Daemonset), 스테이트풀(StatefulSet)와 같은 컨트롤러에 의해 실행된 파드가 축출되면 컨트롤러에 의해 다른 노드로 스케줄링 됩니다. 하지만 이와 같은 컨트롤러를 이용하지 않은 파드는 축출된 후 다른 노드로 스케줄링되지 않습니다. 4. PodDisruptionBudgets(PDB) 설정에 의해 축출에 실패하거나 느려질 수 있습니다. PodDisruptionBudgets(PDB) 설정으로 유지해야 할 파드 수를 정의할 수 있습니다. 이 기능 설정으로 인해 업그레이드 과정에서 파드 축출이 불가능할 수도 있고, 파드 축출 시간이 길어질 수 있습니다. 파드 축출에 실패하면 업그레이드가 실패합니다. 따라서 PDB 설정이 되어 있는 경우 적절한 PDB 설정으로 파드 축출이 원활히 동작할 수 있도록 설정해야 합니다. PDB 설정에 대한 더 자세한 내용은 여기를 참고하세요.
안전한 파드 축출에 대한 좀 더 상세한 설명은 Safely Drain a Node를 참고하세요
시스템 파드 업그레이드
마스터와 모든 워커 노드 그룹을 업그레이드하여 버전이 일치하게 되면 Kubernetes 클러스터 구성을 위해 동작하는 시스템 파드가 업그레이드 됩니다.
[주의] 마스터 업그레이드 후 워커 노드 그룹을 업그레이드하지 않으면 일부 파드가 정상적으로 동작하지 않을 수 있습니다.
클러스터 CNI 변경
NHN Kubernetes Service(NKS)는 동작 중인 Kubernetes 클러스터의 CNI(container network interface) 변경을 지원합니다. 클러스터 CNI 변경 기능을 사용하면 NHN Kubernetes Service(NKS)의 CNI가 Flannel CNI에서 Calico CNI로 변경됩니다.
CNI 변경 규칙
NHN Cloud의 Kubernetes 클러스터 CNI 변경 기능에 적용되는 규칙은 다음과 같습니다.
- CNI 변경 기능은 NHN Kubernetes Service(NKS) 버전 1.24.3 이상인 경우에 사용할 수 있습니다.
- 기존 NHN Kubernetes Service(NKS)에서 사용하고 있는 CNI가 Flannel인 경우에만 CNI 변경을 사용할 수 있습니다.
- CNI 변경 시작 시 마스터와 모든 워커 노드 그룹에 대해 일괄적으로 작업을 진행합니다.
- 마스터의 Kubernetes 버전과 모든 워커 노드 그룹의 Kubernetes 버전이 일치해야 CNI 변경이 가능합니다.
- Calico에서 Flannel로 CNI 변경은 지원하지 않습니다.
- 다른 기능의 동작으로 인해 클러스터가 업데이트 중인 상태에서는 CNI 변경이 불가능합니다.
다음 예시는 Kubernetes CNI 변경 과정에서 변경 가능 여부를 표로 나타낸 것입니다. 예시에 사용된 조건은 다음과 같습니다.
NHN Cloud가 지원하는 Kubernetes 버전 목록: v1.23.3, v1.24.3, v1.25.4 클러스터는 v1.23.3으로 생성
| 상태 | 클러스터 버전 | 현재 CNI | CNI 변경 가능 여부 |
|---|---|---|---|
| 초기 상태 | v1.23.3 | Flannel | 불가능 1 |
| 클러스터 업그레이드 후 상태 | v1.24.3 | Flannel | 가능 2 |
| CNI 변경 후 상태 | v1.24.3 | Calico | 불가능 3 |
주석
- 1: 클러스터 버전이 1.24.3 미만이기 때문에 CNI 변경 불가능
- 2: 클러스터 버전이 1.24.3 이상이기 때문에 CNI 변경 가능
- 3: CNI가 이미 Calico이므로 CNI 변경 불가능
Flannel에서 Calico CNI로 변경 진행 과정
CNI 변경은 다음 순서로 진행됩니다.
- 모든 워커 노드 그룹에 버퍼 노드1를 추가합니다.2
- 클러스터에 Calico CNI가 배포됩니다.3
- 클러스터 오토스케일러 기능을 비활성화합니다.4
- 모든 워커 노드 그룹 내의 모든 워커 노드에 대해 순차적으로 아래 작업을 수행합니다.5
- 해당 워커 노드에서 동작 중인 파드를 축출하고, 노드를 스케줄 불가능한 상태로 전환합니다.
- 워커 노드의 파드 IP를 Calico CIDR로 재할당합니다. 해당 노드에 배포되어 있는 모든 파드는 재배포됩니다.6
- 노드를 스케줄 가능한 상태로 전환합니다.
- 버퍼 노드에서 동작 중인 파드를 축출하고 버퍼 노드를 삭제합니다.
- 클러스터 오토스케일러 기능을 다시 활성화합니다.4
- Flannel CNI를 제거합니다.
주석
- 1: 버퍼 노드란 CNI 변경 과정 중 기존 워커 노드에서 축출된 파드가 다시 스케줄링될 수 있도록 생성해 두는 여유 노드를 말합니다. 해당 워커 노드 그룹에서 정의한 워커 노드와 동일한 규격의 노드로 생성되며, 업그레이드 과정이 종료될 때 자동으로 삭제됩니다. 이 노드는 Instance 요금 정책에 따라 비용이 청구됩니다.
- 2: CNI 변경 시 버퍼 노드 수를 설정할 수 있습니다. 기본값은 1이며, 0으로 설정하면 버퍼 노드를 추가하지 않습니다. 최솟값은 0이고, 최댓값은 (노드 그룹당 최대 노드 수 쿼터-해당 워커 노드 그룹의 현재 노드 수)입니다.
- 3: 클러스터에 Calico CNI가 배포되면 Flannel과 Calico CNI가 공존하게 됩니다. 이 상태에서 새로운 파드가 배포되면 파드 IP는 Flannel CNI로 설정되어 배포됩니다. Flannel CIDR IP를 가진 파드와 Calico CIDR IP를 가진 파드는 서로 통신할 수 있습니다.
- 4: 이 단계는 업그레이드 기능 시작 전 클러스터 오토스케일러 기능이 활성화되어 있는 경우에만 유효합니다.
- 5: CNI 변경 시 설정한 최대 서비스 불가 노드 수만큼씩 작업을 수행합니다. 기본값은 1입니다. 최솟값은 1이고, 최댓값은 현재 클러스터의 모든 노드 수입니다.
- 6: 기존에 배포되어 있는 파드의 IP는 모두 Flannel CIDR로 할당되어있습니다. Calico CNI로 변경하기 위해 Flannel CIDR의 IP가 할당되어 있는 파드들을 모두 재배포하여 Calico CIDR IP를 할당합니다. 새로운 파드가 배포되면 파드 IP는 Calico CNI로 설정되어 배포됩니다.
이 과정에서 아래와 같은 일들이 발생할 수 있습니다.
- 서비스 중인 파드가 축출되어 다른 노드로 스케줄링됩니다. (파드 축출에 대한 더 자세한 내용은 클러스터 업그레이드를 참고하시길 바랍니다.)
- 클러스터에 배포되어있는 모든 파드가 재배포 됩니다. (파드 재배포에 대한 더 자세한 내용은 아래 파드 재배포 주의 사항을 참고하시길 바랍니다.)
- 오토스케일러 기능이 동작하지 않습니다.
[파드 재배포 주의 사항] 1. 파드 축출 과정을 통해 다른 노드로 옮겨지지 않은 파드에 대해 진행됩니다. 2. CNI 변경 과정 중에 Flannel CIDR와 Calico CIDR 간 정상 통신을 위해 CNI 변경 파드 네트워크 값은 기존 Flannel CIDR값과 동일하면 안됩니다. 3. 기존에 배포되어 있던 파드들의 pause 컨테이너는 모두 stop 되어졌다가 kubelet에 의해 다시 재생성됩니다. 파드 이름과 로컬 저장 공간 등 설정은 그대로 유지되지만 IP는 Calico CIDR의 IP로 변경됩니다.
클러스터 API 엔드포인트 IP 접근 제어 적용
클러스터 API 엔드포인트에 IP 접근 제어를 적용하거나 해제할 수 있습니다. IP 접근 제어 기능에 대한 자세한 사항은 IP 접근제어 문서를 참고하세요.
IP 접근 제어 대상 규칙
클러스터 API 엔드포인트 IP 접근 제어 대상을 추가하는 경우 아래의 규칙이 적용됩니다.
- IP 접근 제어 타입이 허용으로 설정된 경우 클러스터 기본 서브넷 CIDR이 접근 제어 대상에 자동으로 추가됩니다.
- IP 접근 제어 타입이 허용으로 설정된 경우 NKS 콘솔의 대시보드, 네임스페이스, 워크로드, 서비스&네트워크, 스토리지, 설정, 이벤트 탭이 비활성화됩니다.
- IP 접근 제어 타입이 차단으로 설정된 경우 클러스터 기본 서브넷 CIDR 대역에 중첩되는 IP 대역이 접근 제어 대상 목록에 있으면 요청이 거절됩니다.
- 최대 설정 가능한 IP 접근 제어 대상 수는 100개입니다.
- IP 접근 제어 대상은 1개 이상 존재해야 합니다.
워커 노드 관리
컨테이너 관리
Kubernetes v1.24.3 이전 버전의 클러스터
Kubernetes v1.24.3 이전 버전의 클러스터는 Docker를 이용해 컨테이너 런타임을 구성합니다. 워커 노드에서 docker CLI를 이용해 컨테이너 상태 조회, 컨테이너 이미지 조회 등의 작업을 할 수 있습니다. docker CLI에 대한 자세한 설명과 사용법은 Use the Docker command line을 참고하세요.
Kubernetes v1.24.3 이후 버전의 클러스터
Kubernetes v1.24.3 이후 버전의 클러스터는 containerd를 이용해 컨테이너 런타임을 구성합니다. 워커 노드에서 docker CLI 대신 nerdctl을 이용해 컨테이너 상태 조회, 컨테이너 이미지 조회 등의 작업을 할 수 있습니다. nerdctl에 대한 자세한 설명과 사용법은 nerdctl: Docker-compatible CLI for containerd를 참고하세요.
네트워크 관리
기본 네트워크 인터페이스
모든 워커 노드는 클러스터 생성 시 입력한 VPC/서브넷에 연결되는 네트워크 인터페이스를 가지고 있습니다. 이 기본 네트워크 인터페이스의 이름은 "eth0"이며, 워커 노드는 이 네트워크 인터페이스를 통해 마스터와 연결됩니다.
추가 네트워크 인터페이스
클러스터 또는 워커 노드 그룹 생성 시 추가 네트워크를 설정하면 해당 워커 노드 그룹의 워커 노드에 추가 네트워크 인터페이스가 생성됩니다. 추가 네트워크 인터페이스는 추가 네트워크 설정에 입력한 순서대로 인터페이스 이름이 설정됩니다(eth1, eth2, ...).
기본 경로(default route) 설정
워커 노드에 여러 네트워크 인터페이스가 존재하는 경우, 각 네트워크 인터페이스별로 기본 경로가 설정됩니다. 한 시스템에 여러 기본 경로가 설정된 경우, 메트릭(metric) 값이 가장 낮은 기본 경로가 시스템 기본 경로로 동작합니다. 네트워크 인터페이스별 기본 경로는 인터페이스 번호가 작을수록 낮은 메트릭 값이 설정되어 있습니다. 이로 인해 동작 중인 네트워크 인터페이스 중 가장 작은 번호의 네트워크 인터페이스가 시스템 기본 경로로 동작합니다.
시스템 기본 경로를 추가 네트워크 인터페이스로 설정하기 위해서는 아래와 같은 작업이 필요합니다.
1. 네트워크 인터페이스별 메트릭 설정 변경
워커 노드의 모든 네트워크 인터페이스는 DHCP 서버를 통해 IP 주소를 할당 받습니다. DHCP 서버로부터 IP 주소를 할당받을 때 네트워크 인터페이스별 기본 경로를 설정합니다. 이 때 각 기본 경로의 메트릭 값은 인터페이스별로 미리 설정되어 있습니다. 리눅스 배포판별 저장 위치 및 설정 항목은 다음과 같습니다.
- CentOS
- 설정 파일 위치: /etc/sysconfig/network-scripts/ifcfg-{네트워크 인터페이스 이름}
- 메트릭 값 설정 항목: METRIC
- Ubuntu
- 설정 파일 위치: /etc/systemd/network/toastcloud-{네트워크 인터페이스 이름}.network
- 메트릭 값 설정 항목: DHCP 섹션의 RouteMetric
[주의] 기본 경로별 메트릭 값은 기본 경로가 설정되는 시점에 결정됩니다. 따라서 변경된 설정은 다음 기본 경로 설정 시점에 적용됩니다. 현재 시스템에 적용된 경로별 메트릭 값을 변경하기 위해서는 아래
현재 경로의 메트릭 값 변경을 참고하세요.
2. 현재 경로의 메트릭 값 변경
시스템 기본 경로를 변경하기 위해서 네트워크 인터페이스별 기본 경로의 메트릭 값을 조정할 수 있습니다. 다음은 route 명령어를 이용해 각 기본 경로의 메트릭 값을 조정하는 예제입니다.
다음은 작업 실행 전의 상태입니다. 인터페이스 번호가 작을수록 메트릭 값이 작게 설정된 것을 확인할 수 있습니다.
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.0.1 0.0.0.0 UG 0 0 0 eth0
0.0.0.0 192.168.0.1 0.0.0.0 UG 100 0 0 eth1
0.0.0.0 172.16.0.1 0.0.0.0 UG 200 0 0 eth2
...
eth1을 시스템 기본 경로로 설정하기 위해 eth1의 메트릭 값을 0으로, eth0의 메트릭 값을 100으로 변경합니다. 메트릭 값만 변경할 수는 없기 떄문에 경로를 삭제하고 다시 추가해야 합니다. 먼저 eth0의 경로를 삭제하고 eth0의 메트릭 값을 100으로 설정합니다.
# route del -net 0.0.0.0/0 dev eth0
# route add -net 0.0.0.0/0 gw 10.0.0.1 dev eth0 metric 100
eth1도 먼저 기존 경로를 삭제하고, eth1의 메트릭을 0으로 설정합니다.
# route del -net 0.0.0.0/0 dev eth1
# route add -net 0.0.0.0/0 gw 192.168.0.1 dev eth1 metric 0
다시 경로를 조회해 보면 메트릭 값이 변경된 것을 확인할 수 있습니다.
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.0.1 0.0.0.0 UG 0 0 0 eth1
0.0.0.0 10.0.0.1 0.0.0.0 UG 100 0 0 eth0
0.0.0.0 172.16.0.1 0.0.0.0 UG 200 0 0 eth2
...
사용자 스크립트 기능을 이용한 기본 경로 설정 변경
사용자 스크립트 기능을 이용하면 노드 증설 등으로 노드가 새롭게 초기화될 때도 위와 같은 설정을 유지할 수 있습니다. 다음 사용자 스크립트는 CentOS를 사용하는 워커 노드에서 eth0의 메트릭 값을 100으로, eth1의 메트릭 값을 0으로 설정하는 예제입니다. 이렇게 하면 현재 시스템에 적용되어 있는 기본 경로별 메트릭 값도 변경되며, 이는 워커 노드 재시작 후에도 유지됩니다.
#!/bin/bash
sed -i -e 's|^METRIC=.*$|METRIC=100|g' /etc/sysconfig/network-scripts/ifcfg-eth0
sed -i -e 's|^METRIC=.*$|METRIC=0|g' /etc/sysconfig/network-scripts/ifcfg-eth1
route del -net 0.0.0.0/0 dev eth0
route add -net 0.0.0.0/0 gw 10.0.0.1 dev eth0 metric 100
route del -net 0.0.0.0/0 dev eth1
route add -net 0.0.0.0/0 gw 192.168.0.1 dev eth1 metric 0
kubelet 사용자 정의 아규먼트 설정 기능
kubelet은 모든 워커 노드에서 동작하는 노드 에이전트입니다. kubelet은 커맨드라인 아규먼트를 이용해 여러 설정을 입력 받습니다. NKS에서 제공하는 kubelet 사용자 정의 아규먼트 설정 기능을 이용하면 kubelet 시작 시 입력되는 아규먼트를 추가할 수 있습니다. kubelet 사용자 정의 아규먼트는 다음과 같이 설정하고 시스템에 적용할 수 있습니다.
- 워커 노드의
/etc/kubernetes/kubelet-user-args파일에KUBELET_USER_ARGS="사용자 정의 아규먼트"형식으로 사용자 정의 아규먼트를 입력합니다. systemctl daemon-reload명령을 수행합니다.systemctl restart kubelet명령을 수행합니다.systemctl status kubelet명령으로 kubelet이 정상 동작 중인지 확인합니다.
[주의] * 이 기능은 2023년 11월 30일 이후 신규 생성된 클러스터에서만 동작합니다. * 사용자 정의 아규먼트를 설정할 워커 노드별로 수행합니다. * 올바르지 않은 형식의 사용자 정의 아규먼트 입력 시 kubelet이 정상 동작하지 않습니다. * 설정된 사용자 정의 아규먼트는 시스템 재시작 시에도 그대로 적용됩니다.
사용자 정의 containerd 레지스트리 설정 기능
v1.24.3 이상의 NKS 클러스터는 컨테이너 런타임으로 containerd v1.6을 사용합니다. NKS에서는 containerd의 여러 가지 설정 중 레지스트리와 관련된 항목을 사용자 환경에 맞게 설정할 수 있는 기능을 제공합니다. containerd v1.6의 레지스트리 설정은 Configure Image Registry를 참고하세요.
워커 노드가 초기화되는 과정 중 사용자 정의 containerd 레지스트리 설정 파일(/etc/containerd/registry-config.json)이 존재하면 이 파일의 내용을 containerd 설정 파일(/etc/containerd/config.toml)에 적용합니다. 사용자 정의 containerd 레지스트리 설정 파일이 존재하지 않으면 containerd 설정 파일에는 기본 레지스트리 설정이 적용됩니다. 기본 레지스트리 설정의 내용은 다음과 같습니다.
[
{
"registry": "docker.io",
"endpoint_list": [
"https://registry-1.docker.io"
]
}
]
하나의 레지스트리에 대해 설정할 수 있는 키/값 형식은 다음과 같습니다.
{
"registry": "REGISTRY_NAME",
"endpoint_list": [
"ENDPOINT1",
"ENDPOINT2"
],
"tls": {
"ca_file": "CA_FILEPATH",
"cert_file": "CERT_FILEPATH",
"key_file": "KEY_FILEPATH",
"insecure_skip_verify": true_or_false
},
"auth": {
"username": "USERNAME",
"password": "PASSWORD",
"auth": "AUTH",
"identitytoken": "IDENTITYTOKEN"
}
}
예시1
docker.io 이외에 추가 레지스트리를 등록하려면 다음과 같이 설정할 수 있습니다.
[
{
"registry": "docker.io",
"endpoint_list": [
"https://registry-1.docker.io"
]
},
{
"registry": "additional.registry.io",
"endpoint_list": [
"https://additional.registry.io"
]
}
]
예시2
docker.io 레지스트리를 제거하고 HTTP를 지원하는 레지스트리만 등록하려면 다음과 같이 설정할 수 있습니다.
[
{
"registry": "user-defined.registry.io",
"endpoint_list": [
"http://user-defined.registry.io"
],
"tls": {
"insecure_skip_verify": true
}
}
]
예시3
노드 생성 시 사용자 정의 containerd 레지스트리 설정 파일을 예시2의 내용으로 생성하기 위해서 사용자 스크립트를 다음과 같이 설정할 수 있습니다.
mkdir -p /etc/containerd
echo '[ { "registry": "user-defined.registry.io", "endpoint_list": [ "http://user-defined.registry.io" ], "tls": { "insecure_skip_verify": true } } ]' > /etc/containerd/registry-config.json
[주의] * containerd 설정 파일(
/etc/containerd/config.toml)은 NKS에 의해 관리되는 파일입니다. 이 파일을 임의로 수정하면 NKS의 기능 동작에 오류가 발생하거나 임의로 수정된 내용이 제거될 수 있습니다. * 사용자 정의 containerd 레지스트리 설정 기능으로 올바르지 못한 레지스트리가 설정되면 워커 노드가 비정상 동작할 수 있습니다. * 사용자 정의 containerd 레지스트리 설정 기능이 containerd 설정 파일에 적용되는 시점은 워커 노드 초기화 과정입니다. 워커 노드 초기화 과정은 워커 노드 생성 과정과 워커 노드 그룹 업그레이드 과정에 포함됩니다. * 워커 노드 생성 시 사용자 정의 container 레지스트리 설정 기능을 적용하기 위해서는 사용자 스크립트에서 이 설정 파일을 생성하도록 해야 합니다. * 워커 노드 그룹 업그레이드 시 사용자 정의 container 레지스트리 설정 기능을 적용하기 위해서는 모든 워커 노드에 이 파일을 수동 설정한 후 업그레이드를 진행해야 합니다. * 사용자 정의 containerd 레지스트리 설정 파일이 존재하는 경우 이 파일에 설정된 내용이 containerd에 그대로 적용됩니다. *docker.io레지스트리를 사용하려면docker.io레지스트리에 대한 설정도 포함되어야 합니다.docker.io레지스트리의 설정은 기본 레지스트리 설정을 참고하세요. *docker.io레지스트리를 사용하지 않으려면docker.io레지스트리에 대한 설정을 포함하지 않으면 됩니다. 단, 하나 이상의 레지스트리 설정이 존재해야 합니다.
LoadBalancer 서비스
Kubernetes 애플리케이션의 기본 실행 단위인 파드(pod)는 CNI(container network interface)로 클러스터 네트워크에 연결됩니다. 기본적으로 클러스터 외부에서 파드로는 접근할 수 없습니다. 파드의 서비스를 클러스터 외부에 공개하려면 Kubernetes의 LoadBalancer 서비스(Service) 객체(object)를 이용해 외부에 공개할 경로를 만들어야 합니다. LoadBalancer 서비스 객체를 만들면 클러스터 외부에 NHN Cloud Load Balancer가 생성되어 서비스 객체와 연결됩니다.
웹 서버 파드 생성
다음과 같이 2개의 nginx 파드를 실행하는 디플로이먼트(deployment) 객체 매니페스트 파일을 작성하고 객체를 생성합니다.
# nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
디플로이먼트 객체를 생성하면 매니페스트에 정의한 파드가 자동으로 생성됩니다.
$ kubectl apply -f nginx.yaml
deployment.apps/nginx-deployment created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-7fd6966748-pvrzs 1/1 Running 0 4m13s
nginx-deployment-7fd6966748-wv7rd 1/1 Running 0 4m13s
LoadBalancer 서비스 생성
Kubernetes의 서비스 객체를 정의하려면 다음과 같은 항목으로 구성된 매니페스트가 필요합니다.
| 항목 | 설명 |
|---|---|
| metadata.name | 서비스 객체의 이름 |
| spec.selector | 서비스 객체와 연결할 파드 이름 |
| spec.ports | 외부 로드 밸런서에서 들어오는 트래픽을 파드에 전달할 인터페이스 설정 |
| spec.ports.name | 인터페이스 이름 |
| spec.ports.protocol | 인터페이스에서 사용할 프로토콜(예: TCP) |
| spec.ports.port | 서비스 객체 외부에 공개할 포트 번호 |
| spec.ports.targetPort | 서비스 객체와 연결할 파드의 포트 번호 |
| spec.type | 서비스 객체 유형 |
다음과 같이 서비스 매니페스트를 작성합니다. 이 LoadBalancer 서비스 객체는 spec.selector에 정의된 이름에 따라 app: nginx 레이블이 붙은 파드와 연결됩니다. 그리고 spec.ports에 정의된 대로 TCP/8080 포트로 들어온 트래픽을 파드의 TCP/80 포트로 전달합니다.
# service.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
labels:
app: nginx
spec:
ports:
- port: 8080
targetPort: 80
protocol: TCP
selector:
app: nginx
type: LoadBalancer
LoadBalancer 서비스 객체를 생성하면 클러스터 외부에 로드 밸런서를 만들고 연결하기까지 약간의 시간이 필요합니다. 외부 로드 밸런서와 연결되기 전에는 EXTERNAL-IP 항목이 <pending>으로 표시됩니다.
$ kubectl apply -f service.yaml
service/nginx-svc created
$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-svc LoadBalancer 10.254.134.18 <pending> 8080:30013/TCP 11s
외부 로드 밸런서와 연결되면 EXTERNAL-IP 항목에 IP가 표시됩니다. 이 IP는 외부 로드 밸런서의 플로팅 IP입니다.
$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-svc LoadBalancer 10.254.134.18 123.123.123.30 8080:30013/TCP 3m13s
[참고] 생성된 로드 밸런서는 Network > Load Balancer 페이지에서 확인할 수 있습니다. 로드 밸런서의 IP는 외부에서 접근할 수 있는 플로팅 IP입니다. Network > Floating IP 페이지에서 확인할 수 있습니다.
인터넷을 통한 서비스 테스트
로드 밸런서에 연결된 플로팅 IP로 HTTP 요청을 보내 Kubernetes 클러스터의 웹 서버 파드가 응답하는지 확인합니다. 서비스 객체의 TCP/8080 포트를 파드의 TCP/80 포트와 연결하도록 설정했기 때문에 TCP/8080 포트로 요청을 보내야 합니다. 외부 로드 밸런서와 서비스 객체, 파드가 잘 연결되었다면 웹 서버는 nginx 기본 페이지를 응답합니다.
$ curl http://123.123.123.30:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
로드 밸런서 상세 옵션 설정
Kubernetes의 서비스 객체를 정의할 때 로드 밸런서의 여러 가지 옵션을 설정할 수 있습니다. 설정 가능한 항목은 아래와 같습니다.
- 전역 설정과 리스너별 설정
- 리스너별 설정 형식
- 로드 밸런서 이름 설정
- keep-alive 타임아웃 설정
- 로드 밸런서 타입 설정
- 세션 지속성 설정
- 로드 밸런서 삭제 시 플로팅 IP 주소 보존 여부 설정
- 로드 밸런서 IP 설정
- 플로팅 IP 사용 여부 설정
- VPC 설정
- 서브넷 설정
- 멤버 서브넷 설정
- 리스너 연결 제한 설정
- 리스너 프로토콜 설정
- 리스너 프록시 프로토콜(Proxy Protocol) 설정
- 로드 밸런싱 방식 설정
- 상태 확인 프로토콜 설정
- 상태 확인 주기 설정
- 상태 확인 최대 응답 시간 설정
- 상태 확인 최대 재시도 횟수 설정
전역 설정과 리스너별 설정
설정 항목별로 전역 설정과 리스너별 설정이 가능합니다. 전역 설정과 리스너별 설정 모두 없는 경우 설정별 기본값을 사용합니다. * 리스너별 설정: 대상 리스너에만 적용되는 설정입니다. * 전역 설정: 대상 리스너에 리스너별 설정이 없는 경우 이 설정을 적용합니다.
리스너별 설정 형식
리스너별 설정은 전역 설정 키에 리스너를 나타내는 접두어(prefix)를 붙여 설정할 수 있습니다. 리스너를 나타내는 접두어는 서비스 객체의 포트 프로토콜(spec.ports[].protocol)과 포트 번호(spec.ports[].port)를 대시(-)로 연결한 것입니다. 예를 들어 프로토콜이 TCP이고, 포트 번호가 80인 경우 접두어는 TCP-80입니다. 이 포트와 연결되는 리스너에 세션 지속성 설정을 하고 싶다면 .metadata.annotations 하위의 TCP-80.loadbalancer.nhncloud/pool-session-persistence에 설정할 수 있습니다.
아래 매니페스트는 전역 설정과 리스너별 설정을 혼용한 예제입니다.
apiVersion: v1
kind: Service
metadata:
name: echosvr-svc
labels:
app: echosvr
annotations:
# 전역 설정
loadbalancer.nhncloud/pool-lb-method: SOURCE_IP
# 리스너별 설정
TCP-80.loadbalancer.nhncloud/pool-session-persistence: "SOURCE_IP"
TCP-80.loadbalancer.nhncloud/listener-protocol: "HTTP"
TCP-443.loadbalancer.nhncloud/pool-lb-method: LEAST_CONNECTIONS
TCP-443.loadbalancer.nhncloud/listener-protocol: "TCP"
spec:
ports:
- name: tcp-80
port: 80
targetPort: 8080
protocol: TCP
- name: tcp-443
port: 443
targetPort: 8443
protocol: TCP
selector:
app: echosvr
type: LoadBalancer
이 매니페스트를 적용했을 때 리스너별 설정은 다음 표와 같이 설정됩니다.
| 항목 | TCP-80 리스너 | TCP-433 리스너 | 설명 |
|---|---|---|---|
| 로드 밸런싱 방식 | SOURCE_IP | LEAST_CONNECTIONS | TCP-80 리스너는 전역 설정에 따라 SOURCE_IP로 설정 TCP-443 리스너는 리스너별 설정에 따라 LEAST_CONNECTIONS로 설정 |
| 세션 지속성 | SOURCE_IP | None | TCP-80 리스너는 리스너별 설정에 따라 SOURCE_IP로 설정 TCP-443 리스너는 기본값에 따라 None으로 설정 |
| 리스너 프로토콜 | HTTP | TCP | TCP-80 리스너와 TCP-443 리스너 모두 리스너별 설정에 따라 설정 |
[참고] 별도로 표시되어 있지 않은 기능은 Kubernetes v1.19.13 이후 버전의 클러스터에만 적용 가능합니다.
[주의] 아래 기능의 설정값은 모두 문자열 형식으로 입력해야 합니다. YAML 파일 입력 형식에서 입력값 형태에 관계없이 문자열 형식으로 입력하기 위해서는 입력값을 큰따옴표(")로 감싸주면 됩니다. YAML 파일 형식에 대한 더 자세한 내용은 Yaml Cookbook 문서를 참조하세요.
로드 밸런서 이름 설정
로드 밸런서의 이름을 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/loadbalancer-name입니다.
- 리스너별 설정을 적용할 수 없습니다.
- 영문자와 숫자, '-', '_'만 입력 가능합니다.
- 유효하지 않은 문자가 포함된 경우 기본 로드 밸런서 이름 양식에 따라 로드 밸런서 이름이 설정됩니다.
- 기본 로드 밸런서 이름 양식: "kube_service_{CLUSTER_UUID}_{SERVICE_NAMESPACE}_{SERVICE_NAME}"
- 최대 길이는 255자이며, 최대 길이 초과 시 로드 밸런서 이름은 255자로 잘립니다.
[주의] 다음 행위를 하는 경우 로드 밸런서의 심각한 오동작을 초래할 수 있습니다. * 서비스 객체가 생성된 후 로드 밸런서 이름을 수정 * 프로젝트 내에 같은 이름의 로드 밸런서를 생성
로드 밸런서 타입 설정
로드 밸런서의 타입을 설정할 수 있습니다. 로드 밸런서에 대한 자세한 내용은 로드 밸런서 콘솔 사용 가이드를 참고하세요.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/loadbalancer-type입니다.
- 리스너별 설정을 적용할 수 없습니다.
- 다음 중 하나로 설정할 수 있습니다.
- shared: '일반' 타입의 로드 밸런서를 생성합니다. 미설정 시 기본값입니다.
- dedicated: '전용' 타입의 로드 밸런서를 생성합니다.
세션 지속성 설정
로드 밸런서의 세션 지속성을 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/pool-session-persistence입니다.
- 리스너별 설정을 적용할 수 있습니다.
- 다음 중 하나로 설정할 수 있습니다.
- 빈 문자열(""): 세션 지속성을 '없음'으로 설정합니다. 미설정 시 기본값입니다.
- SOURCE_IP: 세션 지속성을 SOURCE_IP로 설정합니다.
- 로드 밸런싱 방식이 SOURCE_IP인 경우 세션 지속성 설정은 무시되고, 세션 지속성 설정은 '없음'으로 설정됩니다.
- v1.17.6, v1.18.19 클러스터
- 로드 밸런서 생성 후에는 변경이 불가능합니다.
- v1.19.13 이후 클러스터
- 로드 밸런서 생성 후에도 변경 가능합니다.
로드 밸런서 삭제 시 플로팅 IP 주소 보존 여부 설정
로드 밸런서에는 플로팅 IP가 연결되어 있습니다. 로드 밸런서 삭제 시 로드 밸런서에 연결된 플로팅 IP의 삭제 혹은 보존 여부를 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.openstack.org/keep-floatingip입니다.
- 리스너별 설정을 적용할 수 없습니다.
- 다음 중 하나로 설정할 수 있습니다.
- true: 플로팅 IP를 보존합니다.
- false: 플로팅 IP를 삭제합니다. 미설정 시 기본값입니다.
로드 밸런서 IP 설정
로드 밸런서를 생성할 때 로드 밸런서의 IP를 설정할 수 있습니다.
- 설정 위치는 .spec.loadBalancerIP 입니다.
- 리스너별 설정을 적용할 수 없습니다.
- 다음 중 하나로 설정할 수 있습니다.
- 빈 문자열(""): 로드 밸런서에 자동으로 생성되는 플로팅 IP를 연결합니다. 미설정 시 기본값입니다.
: 로드 밸런서에 기존의 플로팅 IP를 연결합니다. 이미 할당 받았지만 연결되지 않은 플로팅 IP가 있을 때 사용 가능합니다.
아래는 로드 밸런서에 사용자 지정 플로팅 IP를 연결하는 매니페스트 예제입니다.
# service-fip.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc-floatingIP
labels:
app: nginx
spec:
loadBalancerIP: <Floating_IP>
ports:
- port: 8080
targetPort: 80
protocol: TCP
selector:
app: nginx
type: LoadBalancer
플로팅 IP 사용 여부 설정
로드 밸런서 생성 시 플로팅 IP의 사용 여부를 설정할 수 있습니다.
- 설정 위치는 .metadata.annotaions 하위의 service.beta.kubernetes.io/openstack-internal-load-balancer입니다.
- 리스너별 설정을 적용할 수 없습니다.
- 다음 중 하나로 설정할 수 있습니다.
- true: 플로팅 IP를 사용하지 않고, VIP(Virtual IP)를 사용합니다.
- false: 플로팅 IP를 사용합니다. 미설정 시 기본값입니다.
- VIP를 사용하는 경우 .spec.loadBalancerIP 항목을 함께 설정하여 로드 밸런서에 자동으로 생성되는 VIP를 연결하는 대신 VIP를 지정하여 연결할 수 있습니다.
아래는 로드 밸런서에 사용자 지정 VIP를 연결하는 매니페스트 예제입니다.
# service-vip.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc-fixedIP
labels:
app: nginx
annotations:
service.beta.kubernetes.io/openstack-internal-load-balancer: "true"
spec:
loadBalancerIP: <Virtual_IP>
ports:
- port: 8080
targetPort: 80
protocol: TCP
selector:
app: nginx
type: LoadBalancer
플로팅 IP 사용 여부 설정과 로드 밸런서 IP 설정의 조합에 의해 다음과 같이 동작합니다.
| 플로팅 IP 사용 여부 설정 | 로드 밸런서 IP 설정 | 설명 |
|---|---|---|
| false | 미설정 | 로드 밸런서에 플로팅 IP를 생성해 연결합니다. |
| false | 설정 | 로드 밸런서에 지정된 플로팅 IP를 연결합니다. |
| true | 미설정 | 로드 밸런서에 연결되는 VIP를 자동으로 설정합니다. |
| true | 설정 | 로드 밸런서에 지정된 VIP를 연결합니다. |
VPC 설정
로드 밸런서 생성 시 로드 밸런서가 연결될 VPC를 설정할 수 있습니다.
- 설정 위치는 .metadata.annotaions 하위의 loadbalancer.openstack.org/network-id입니다.
- 리스너별 설정을 적용할 수 없습니다.
- 설정하지 않으면 클러스터 생성 시 설정한 VPC로 설정합니다.
서브넷 설정
로드 밸런서 생성 시 로드 밸런서가 연결될 서브넷을 설정할 수 있습니다. 설정된 서브넷에 로드 밸런서의 사설 IP가 연결됩니다. 멤버 서브넷 설정이 없는 경우 이 서브넷에 연결된 워커 노드가 로드 밸런서 멤버로 추가됩니다.
- 설정 위치는 .metadata.annotaions 하위의 loadbalancer.openstack.org/subnet-id입니다.
- 리스너별 설정을 적용할 수 없습니다.
- 설정하지 않으면 클러스터 생성 시 설정한 서브넷으로 설정합니다.
아래는 로드 밸런서에 VPC와 서브넷을 설정하는 매니페스트 예제입니다.
apiVersion: v1
kind: Service
metadata:
name: nginx-svc-vpc-subnet
labels:
app: nginx
annotations:
loadbalancer.openstack.org/network-id: "49a5820b-d941-41e5-bfc3-0fd31f2f6773"
loadbalancer.openstack.org/subnet-id: "38794fd7-fd2e-4f34-9c89-6dd3fd12f548"
spec:
ports:
- port: 8080
targetPort: 80
protocol: TCP
selector:
app: nginx
type: LoadBalancer
멤버 서브넷 설정
로드 밸런서 생성 시 로드 밸런서 멤버가 연결될 서브넷을 설정할 수 있습니다. 이 서브넷에 연결된 워커 노드가 로드 밸런서 멤버로 추가됩니다.
- 설정 위치는 .metadata.annotaions 하위의 loadbalancer.nhncloud/member-subnet-id입니다.
- 리스너별 설정을 적용할 수 없습니다.
- 설정하지 않으면 로드 밸런서의 서브넷 설정값이 적용됩니다.
- 멤버 서브넷은 반드시 로드 밸런서 서브넷과 동일한 VPC에 포함되어 있어야 합니다.
- 2개 이상의 멤버 서브넷을 설정하기 위해서는 콤마로 구분된 목록으로 입력합니다.
아래는 로드 밸런서에 VPC, 서브넷, 멤버 서브넷을 설정하는 매니페스트 예제입니다.
apiVersion: v1
kind: Service
metadata:
name: nginx-svc-vpc-subnet
labels:
app: nginx
annotations:
loadbalancer.openstack.org/network-id: "49a5820b-d941-41e5-bfc3-0fd31f2f6773"
loadbalancer.openstack.org/subnet-id: "38794fd7-fd2e-4f34-9c89-6dd3fd12f548"
loadbalancer.nhncloud/member-subnet-id: "c3548a5e-b73c-48ce-9dc4-4d4c484108bf"
spec:
ports:
- port: 8080
targetPort: 80
protocol: TCP
selector:
app: nginx
type: LoadBalancer
[주의] 멤버 서브넷은 2023년 11월 30일 이후 v1.24.3 이상의 버전으로 업그레이드됐거나 신규 생성된 클러스터에서 설정 가능합니다.
리스너 연결 제한 설정
리스너의 연결 제한을 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/connection-limit입니다.
- 리스너별 설정을 적용할 수 있습니다.
- v1.17.6, v1.18.19 클러스터
- 최소값 1, 최대값 60000입니다.
- 설정하지 않으면 -1로 설정되며, 실제 로드 밸런서에 적용되는 값은 2000입니다.
- v1.19.13 이후 클러스터
- 최소값 1, 최대값 60000입니다.
- 설정하지 않거나 범위에서 벗어나는 값을 입력한 경우 기본값인 60000으로 설정됩니다.
리스너 프로토콜 설정
리스너의 프로토콜을 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/listener-protocol입니다.
- 리스너별 설정을 적용할 수 있습니다.
- 다음 중 하나로 설정할 수 있습니다.
- TCP: 미설정 시 기본값입니다.
- HTTP
- HTTPS
- TERMINATED_HTTPS: TERMINATED_HTTPS로 설정합니다. SSL 버전, 인증서, 개인 키 정보를 추가 설정해야 합니다.
[주의] 리스너 프로토콜 설정은 서비스 객체를 변경해도 로드 밸런서에 적용되지 않습니다. 리스너 프로토콜 설정 변경을 위해서는 서비스 객체 삭제 후 다시 생성해야 합니다. 이 경우 로드 밸런서가 삭제된 후 다시 생성되오니 주의하시길 바랍니다.
SSL 버전은 다음과 같이 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/listener-terminated-https-tls-version입니다.
- 리스너별 설정을 적용할 수 있습니다.
- 다음 중 하나로 설정할 수 있습니다.
- TLSv1.3: 미설정 시 기본값입니다.
- TLSv1.2
- TLSv1.1
- TLSv1.0_2016
- TLSv1.0
- SSLv3
[주의] TLSv1.3은 2022년 3월 29일 이후 생성된 클러스터에서 설정 가능합니다.
인증서 정보는 다음과 같이 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/listener-terminated-https-cert입니다.
- 리스너별 설정을 적용할 수 있습니다.
- 시작줄 및 끝줄을 포함해야 합니다.
개인 키 정보는 다음과 같이 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/listener-terminated-https-key입니다.
- 리스너별 설정을 적용할 수 있습니다.
- 시작줄 및 끝줄을 포함해야 합니다.
다음은 리스너 프로토콜을 TERMINATED_HTTPS로 설정할 때의 매니페스트 예제입니다. 인증서 정보와 개인 키 정보는 일부 생략되어 있습니다.
metadata:
name: echosvr-svc
labels:
app: echosvr
annotations:
loadbalancer.nhncloud/listener-protocol: TERMINATED_HTTPS
loadbalancer.nhncloud/listener-terminated-https-tls-version: TLSv1.2
loadbalancer.nhncloud/listener-terminated-https-cert: |
-----BEGIN CERTIFICATE-----
MIIDZTCCAk0CCQDVfXIZ2uxcCTANBgkqhkiG9w0BAQUFADBvMQswCQYDVQQGEwJL
...
fnsAY7JvmAUg
-----END CERTIFICATE-----
loadbalancer.nhncloud/listener-terminated-https-key: |
-----BEGIN RSA PRIVATE KEY-----
MIIEowIBAAKCAQEAz+U5VNZ8jTPs2Y4NVAdUWLhsNaNjRWQm4tqVPTxIrnY0SF8U
...
u6X+8zlOYDOoS2BuG8d2brfKBLu3As5VAcAPLcJhE//3IVaZHxod
-----END RSA PRIVATE KEY-----
리스너 프록시 프로토콜(Proxy Protocol) 설정
리스너 프로토콜이 TCP 혹은 HTTPS인 경우 리스너에 프록시 프로토콜을 설정할 수 있습니다. 프록시 프로토콜에 대한 자세한 내용은 로드 밸런서 프록시 모드를 참고하세요.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/proxy-protocol입니다.
- 리스너별 설정을 적용할 수 있습니다.
- 다음 중 하나로 설정할 수 있습니다.
- true: 프록시 프로토콜을 활성화합니다.
- false: 프록시 프로토콜을 비활성화합니다. 미설정 시 기본값입니다.
로드 밸런싱 방식 설정
로드 밸런싱 방식을 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/pool-lb-method입니다.
- 리스너별 설정을 적용할 수 있습니다.
- 다음 중 하나로 설정할 수 있습니다.
- ROUND_ROBIN: 미설정 시 기본값입니다.
- LEAST_CONNECTIONS
- SOURCE_IP
상태 확인 프로토콜 설정
상태 확인 프로토콜을 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/healthmonitor-type입니다.
- 리스너별 설정을 적용할 수 있습니다.
- 다음 중 하나로 설정할 수 있습니다.
- HTTP: HTTP URL, HTTP 메서드, HTTP 상태 코드를 추가 설정해야 합니다.
- HTTPS: HTTP URL, HTTP 메서드, HTTP 상태 코드를 추가 설정해야 합니다.
- TCP: 미설정 시 기본값입니다.
HTTP URL은 다음과 같이 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/healthmonitor-http-url입니다.
- 리스너별 설정을 적용할 수 있습니다.
- 설정값은 /으로 시작해야 합니다.
- 설정하지 않거나 규칙에 맞지 않는 값을 입력하면 기본값인 /로 설정됩니다.
HTTP 메서드는 다음과 같이 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/healthmonitor-http-method입니다.
- 리스너별 설정을 적용할 수 있습니다.
- 현재 GET만 지원하고 있으며, 설정하지 않거나 다른 값을 입력하면 기본값인 GET으로 설정됩니다.
HTTP 상태 코드는 다음과 같이 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/healthmonitor-http-expected-code입니다.
- 리스너별 설정을 적용할 수 있습니다.
- 단일값(예: 200), 목록(예: 200,202), 범위(예: 200-204) 형태로 입력할 수 있습니다.
- 설정하지 않거나 규칙에 맞지 않는 값을 입력하면 기본값인 200으로 설정됩니다.
상태 확인 주기 설정
상태 확인 주기를 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/healthmonitor-delay입니다.
- 리스너별 설정을 적용할 수 있습니다.
- 초 단위로 설정합니다.
- 최소값 1, 최대값 5000입니다.
- 설정하지 않거나 범위에서 벗어나는 값을 입력하면 기본값인 60으로 설정됩니다.
상태 확인 최대 응답 시간 설정
상태 확인 최대 응답 시간을 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/healthmonitor-timeout입니다.
- 리스너별 설정을 적용할 수 있습니다.
- 초 단위로 설정합니다.
- 최소값 1, 최대값 5000입니다.
- 이 설정은 반드시 상태 확인 주기 설정 설정값보다 작아야 합니다.
- 설정하지 않거나 범위에서 벗어나는 값을 입력하면 기본값인 30으로 설정됩니다.
- 단, 입력값 혹은 설정값이 상태 확인 주기 설정보다 크면 상태 확인 주기 설정의 1/2로 설정됩니다.
상태 확인 최대 재시도 횟수 설정
상태 확인 최대 재시도 횟수를 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/healthmonitor-max-retries입니다.
- 리스너별 설정을 적용할 수 있습니다.
- 최소값 1, 최대값 10입니다.
- 설정하지 않거나 범위에서 벗어나는 값을 입력하면 기본값인 3으로 설정됩니다.
keep-alive 타임아웃 설정
keep-alive 타임아웃 값을 설정할 수 있습니다.
- 설정 위치는 .metadata.annotations 하위의 loadbalancer.nhncloud/keepalive-timeout입니다.
- 리스너별 설정을 적용할 수 있습니다.
- 초 단위로 설정합니다.
- 최소값 0, 최대값 3600입니다.
- 설정하지 않거나 범위에서 벗어나는 값을 입력하면 기본값인 300으로 설정됩니다.
[주의] keep-alive 타임아웃은 2023년 11월 30일 이후 v1.24.3 이상의 버전으로 업그레이드됐거나 신규 생성된 클러스터에서 설정 가능합니다.
인그레스 컨트롤러
인그레스 컨트롤러(ingress controller)는 인그레스(Ingress) 객체에 정의된 규칙을 참조하여 클러스터 외부에서 내부 서비스로 HTTP와 HTTPS 요청을 라우팅하고 SSL/TSL 종료, 가상 호스팅 등을 제공합니다. 인그레스 컨트롤러와 인그레스에 대한 자세한 내용은 인그레스 컨트롤러, 인그레스 문서를 참고하세요.
NGINX Ingress Controller 설치
NGINX Ingress Controller는 많이 사용되는 인그레스 컨트롤러 중 하나입니다. 자세한 내용은 NGINX Ingress Controller와 NGINX Ingress Controller for Kubernetes 문서를 참고하세요. NGINX Ingress Controller의 설치는 Installation Guide 문서를 참고하세요.
URI 기반 서비스 분기
인그레스 컨트롤러는 URI를 기반으로 서비스를 분기할 수 있습니다. 아래 그림은 URI를 기반으로 서비스를 분기하는 간단한 예제의 구조를 나타냅니다.
서비스와 파드 생성
다음과 같이 서비스와 파드를 생성하기 위한 매니페스트를 작성합니다. tea-svc 서비스에는 tea 파드를 연결하고, coffee-svc 서비스에는 coffee 파드를 연결합니다.
# cafe.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: coffee
spec:
replicas: 3
selector:
matchLabels:
app: coffee
template:
metadata:
labels:
app: coffee
spec:
containers:
- name: coffee
image: nginxdemos/nginx-hello:plain-text
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: coffee-svc
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
name: http
selector:
app: coffee
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: tea
spec:
replicas: 2
selector:
matchLabels:
app: tea
template:
metadata:
labels:
app: tea
spec:
containers:
- name: tea
image: nginxdemos/nginx-hello:plain-text
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: tea-svc
labels:
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
name: http
selector:
app: tea
매니페스트를 적용하고 디플로이먼트, 서비스, 파드가 생성되었는지 확인합니다. 파드는 Running 상태여야 합니다.
$ kubectl apply -f cafe.yaml
deployment.apps/coffee created
service/coffee-svc created
deployment.apps/tea created
service/tea-svc created
# kubectl get deploy,svc,pods
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/coffee 3/3 3 3 27m
deployment.apps/tea 2/2 2 2 27m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/coffee-svc ClusterIP 10.254.171.198 <none> 80/TCP 27m
service/kubernetes ClusterIP 10.254.0.1 <none> 443/TCP 5h51m
service/tea-svc ClusterIP 10.254.184.190 <none> 80/TCP 27m
NAME READY STATUS RESTARTS AGE
pod/coffee-7c86d7d67c-pr6kw 1/1 Running 0 27m
pod/coffee-7c86d7d67c-sgspn 1/1 Running 0 27m
pod/coffee-7c86d7d67c-tqtd6 1/1 Running 0 27m
pod/tea-5c457db9-fdkxl 1/1 Running 0 27m
pod/tea-5c457db9-z6hl5 1/1 Running 0 27m
인그레스(Ingress) 생성
요청 경로에 따라 서비스를 연결하는 인그레스 매니페스트를 작성합니다. 엔드포인트가 /tea인 요청은 tea-svc 서비스에 연결하고 /coffee인 요청은 coffee-svc 서비스에 연결합니다.
# cafe-ingress-uri.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: cafe-ingress-uri
spec:
ingressClassName: nginx
rules:
- http:
paths:
- path: /tea
pathType: Prefix
backend:
service:
name: tea-svc
port:
number: 80
- path: /coffee
pathType: Prefix
backend:
service:
name: coffee-svc
port:
number: 80
인그레스를 생성하고 잠시 후 확인했을 때 ADDRESS 필드에 IP가 설정되어 있어야 합니다.
$ kubectl apply -f cafe-ingress-uri.yaml
ingress.networking.k8s.io/cafe-ingress-uri created
$ kubectl get ingress cafe-ingress-uri
NAME CLASS HOSTS ADDRESS PORTS AGE
cafe-ingress-uri nginx * 123.123.123.44 80 23s
HTTP 요청 전송
외부 호스트에서 ingress의 ADDRESS 필드에 설정된 IP 주소로 HTTP 요청을 전송해 인그레스가 올바르게 설정되었는지 확인합니다.
엔드포인트 /coffee에 대한 요청은 coffee-svc 서비스에 전달되어 coffee 파드가 응답합니다. 응답의 Server name 항목을 보면 coffee 파드들이 라운드-로빈 방식으로 번갈아 응답하는 것을 확인할 수 있습니다.
$ curl 123.123.123.44/coffee
Server address: 10.100.24.21:8080
Server name: coffee-7c86d7d67c-sgspn
Date: 11/Mar/2022:06:28:18 +0000
URI: /coffee
Request ID: 3811d20501dbf948259f4b209c00f2f1
$ curl 123.123.123.44/coffee
Server address: 10.100.24.19:8080
Server name: coffee-7c86d7d67c-tqtd6
Date: 11/Mar/2022:06:28:27 +0000
URI: /coffee
Request ID: ec82f6ab31d622895374df972aed1acd
$ curl 123.123.123.44/coffee
Server address: 10.100.24.20:8080
Server name: coffee-7c86d7d67c-pr6kw
Date: 11/Mar/2022:06:28:31 +0000
URI: /coffee
Request ID: fec4a6111bcc27b9cba52629e9420076
마찬가지로 엔드포인트 /tea에 대한 요청은 tea-svc 서비스에 전달되어 tea 파드가 응답합니다.
$ curl 123.123.123.44/tea
Server address: 10.100.24.23:8080
Server name: tea-5c457db9-fdkxl
Date: 11/Mar/2022:06:28:36 +0000
URI: /tea
Request ID: 11be1b7634a371a26e6bf2d3e72ab8aa
$ curl 123.123.123.44/tea
Server address: 10.100.24.22:8080
Server name: tea-5c457db9-z6hl5
Date: 11/Mar/2022:06:28:37 +0000
URI: /tea
Request ID: 21106246517263d726931e0f85ea2887
정의되지 않은 URI로 요청을 보내면 인그레스 컨트롤러가 404 Not Found를 응답합니다.
$ curl 123.123.123.44/unknown
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
리소스 삭제
테스트에 사용한 자원들은 생성할 때 사용한 매니페스트를 이용해 삭제할 수 있습니다.
$ kubectl delete -f cafe-ingress-uri.yaml
ingress.networking.k8s.io "cafe-ingress-uri" deleted
$ kubectl delete -f cafe.yaml
deployment.apps "coffee" deleted
service "coffee-svc" deleted
deployment.apps "tea" deleted
service "tea-svc" deleted
호스트 기반 서비스 분기
인그레스 컨트롤러는 호스트 이름을 기반으로 서비스를 분기할 수 있습니다. 아래 그림은 호스트 이름을 기반으로 서비스를 분기하는 간단한 예제의 구조를 나타냅니다.
서비스와 파드 생성
URI 기반 서비스 분기와 동일한 매니페스트를 이용해 서비스와 파드를 생성합니다.
인그레스 생성
호스트 이름에 따라 서비스를 연결하는 인그레스 매니페스트를 작성합니다. tea.cafe.example.com 호스트로 들어온 요청은 tea-svc 서비스에 연결하고 coffee.cafe.example.com 호스트로 들어온 요청은 coffee-svc 서비스에 연결합니다.
# cafe-ingress-host.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: cafe-ingress-host
spec:
ingressClassName: nginx
rules:
- host: tea.cafe.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: tea-svc
port:
number: 80
- host: coffee.cafe.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: coffee-svc
port:
number: 80
인그레스를 생성하고 잠시 후 확인했을 때 ADDRESS 필드에 IP가 설정되어 있어야 합니다.
$ kubectl apply -f cafe-ingress-host.yaml
ingress.networking.k8s.io/cafe-ingress-host created
$ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
cafe-ingress-host nginx tea.cafe.example.com,coffee.cafe.example.com 123.123.123.44 80 36s
HTTP Request 전송
외부 호스트에서 인그레스의 ADDRESS에 설정된 IP로 HTTP 요청을 전송합니다. 다만 호스트 이름을 이용해 서비스를 분기하도록 인그레스를 구성했기 때문에 호스트 이름을 이용해 요청을 전송해야 합니다.
[참고] 임의의 호스트 이름을 사용하여 테스트하려면 curl의 --resolve 옵션을 사용합니다. --resolve 옵션은
{호스트 이름}:{포트 번호}:{IP}형식으로 입력합니다. 이는 {호스트 이름}으로 보내는 {포트번호}에 대한 요청을 {IP}로 해석(resolve)하라는 의미입니다./etc/host파일을 열어{IP} {호스트 이름}형식으로 추가할 수도 있습니다.
호스트 coffee.cafe.example.com로 요청을 전송하면 coffee-svc 서비스에 전달되어 coffee 파드가 응답합니다.
$ curl --resolve coffee.cafe.example.com:80:123.123.123.44 http://coffee.cafe.example.com/
Server address: 10.100.24.27:8080
Server name: coffee-7c86d7d67c-fqn6n
Date: 11/Mar/2022:06:40:59 +0000
URI: /
Request ID: 1efb60d29891d6d48b5dcd9f5e1ba66d
호스트 tea.cafe.example.com로 요청을 전송하면 tea-svc 서비스에 전달되어 tea 파드가 응답합니다.
$ curl --resolve tea.cafe.example.com:80:123.123.123.44 http://tea.cafe.example.com/
Server address: 10.100.24.28:8080
Server name: tea-5c457db9-ngrxq
Date: 11/Mar/2022:06:41:39 +0000
URI: /
Request ID: 5a6cc490893636029766b02d2aab9e39
알려지지 않은 호스트로 요청을 보내면 인그레스 컨트롤러가 404 Not Found를 응답합니다.
$ curl 123.123.123.44/unknown
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
Kubernetes 대시보드
NHN Kubernetes Service(NKS)는 기본 웹 UI 대시보드(dashboard)를 제공합니다. Kubernetes 대시보드에 대한 자세한 내용은 웹 UI (대시보드) 문서를 참고하세요.
[주의] * Kubernetes 대시보드는 NKS v1.25.4까지만 기본 제공합니다. * NKS 클러스터 버전을 v1.25.4에서 v1.26.3으로 업그레이드해도 동작 중이던 Kubernetes 대시보드 파드와 관련 리소스는 그대로 유지됩니다. * NHN Cloud 콘솔에서 Kubernetes 리소스를 조회할 수 있습니다.
대시보드 서비스 공개
사용자 Kubernetes에는 대시보드를 공개하기 위한 kubernetes-dashboard 서비스 객체가 미리 생성되어 있습니다.
$ kubectl get svc kubernetes-dashboard -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard ClusterIP 10.254.85.2 <none> 443/TCP 6h
$ kubectl describe svc kubernetes-dashboard -n kube-system
Name: kubernetes-dashboard
Namespace: kube-system
Labels: k8s-app=kubernetes-dashboard
Annotations: <none>
Selector: k8s-app=kubernetes-dashboard
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.254.85.2
IPs: 10.254.85.2
Port: <unset> 443/TCP
TargetPort: 8443/TCP
Endpoints: 10.100.24.7:8443
Session Affinity: None
Events: <none>
그러나 kubernetes-dashboard 서비스 객체는 ClusterIP 유형이기 때문에 아직 클러스터 외부에 공개되어 있지 않습니다. 대시보드를 외부 공개하려면 서비스 객체를 LoadBalancer 유형으로 변경하거나 인그레스 컨트롤러와 인그레스 객체를 생성해야 합니다.
LoadBalancer 서비스 객체로 변경
LoadBalancer 유형으로 서비스 객체를 변경하면 클러스터 외부에 NHN Cloud Load Balancer가 생성되고, 로드 밸런서와 서비스 객체와 연결됩니다. 로드 밸런서와 연결된 서비스 객체를 조회하면 EXTERNAL-IP 필드에 로드 밸런서의 IP가 표시됩니다. LoadBalancer 유형의 서비스 객체에 대한 설명은 LoadBalancer 서비스를 참고하세요. 아래 그림은 LoadBalancer 유형의 서비스를 이용해 대시보드를 외부에 공개하는 구조를 나타냅니다.
다음과 같이 kubernetes-dashboard 서비스 객체의 유형을 LoadBalancer로 변경합니다.
$ kubectl -n kube-system patch svc/kubernetes-dashboard -p '{"spec":{"type":"LoadBalancer"}}'
service/kubernetes-dashboard patched
kubernetes-dashboard 서비스 객체가 LoadBalancer 유형으로 변경되면 잠시 후 EXTERNAL-IP 필드에서 로드 밸런서 IP를 확인할 수 있습니다.
$ kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
kubernetes-dashboard LoadBalancer 10.254.95.176 123.123.123.81 443:30963/TCP 2d23h
[참고] 생성된 로드 밸런서는 Network > Load Balancer 페이지에서 확인할 수 있습니다. 로드 밸런서의 IP는 외부에서 접근할 수 있는 플로팅 IP입니다. Network > Floating IP 페이지에서 확인할 수 있습니다.
웹 브라우저에서 https://{EXTERNAL-IP}로 접속하면 Kubernetes 대시보드 페이지가 로딩됩니다. 로그인을 위해 필요한 토큰은 대시보드 엑세스 토큰을 참고하세요.
[참고] Kubernetes 대시보드는 자동 생성되는 사설 인증서를 사용하기 때문에 웹 브라우저의 종류와 보안 설정에 따라 안전하지 않은 페이지로 표시될 수 있습니다.
인그레스(Ingress)를 이용한 서비스 공개
인그레스는 클러스터 내부의 여러 서비스들로 접근하기 위한 라우팅을 제공하는 네트워크 객체입니다. 인그레스 객체의 설정은 인그래스 컨트롤러로 구동됩니다. kubernetes-dashboard 서비스 객체를 인그레스를 통해 공개할 수 있습니다. 인그레스와 인그레스 컨트롤러에 대한 설명은 인그레스 컨트롤러를 참고하세요. 아래 그림은 인그레스를 통해 대시보드를 외부에 공개하는 구조를 나타냅니다.
NGINX Ingress Controller 설치를 참고해 NGINX Ingress Controller를 설치하고 LoadBalancer 유형의 서비스를 생성합니다. 그리고 다음과 같이 인그레스 객체 생성을 위한 매니페스트를 작성합니다.
# kubernetes-dashboard-ingress-tls-passthrough.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: k8s-dashboard-ingress
namespace: kube-system
annotations:
ingress.kubernetes.io/ssl-passthrough: "true"
kubernetes.io/ingress.allow-http: "false"
nginx.ingress.kubernetes.io/backend-protocol: HTTPS
nginx.ingress.kubernetes.io/proxy-body-size: 100M
nginx.ingress.kubernetes.io/rewrite-target: /
nginx.org/ssl-backend: kubernetes-dashboard
spec:
ingressClassName: nginx
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: kubernetes-dashboard
port:
number: 443
tls:
- secretName: kubernetes-dashboard-certs
매니페스트를 적용해 인그레스를 생성하고 인그레스 객체의 ADDRESS 필드를 확인합니다.
$ kubectl apply -f kubernetes-dashboard-ingress-tls-passthrough.yaml
ingress.networking.k8s.io/k8s-dashboard-ingress created
$ kubectl get ingress -n kube-system
NAME CLASS HOSTS ADDRESS PORTS AGE
k8s-dashboard-ingress nginx * 123.123.123.44 80, 443 34s
웹 브라우저에서 https://{ADDRESS}로 접속하면 Kubernetes 대시보드 페이지가 로딩됩니다. 로그인을 위해 필요한 토큰은 대시보드 엑세스 토큰을 참고하세요.
대시보드 엑세스 토큰
Kubernetes 대시보드에 로그인하려면 토큰이 필요합니다. 토큰은 다음 명령으로 얻을 수 있습니다.
# SECRET_NAME=$(kubectl -n kube-system get secrets | grep "kubernetes-dashboard-token" | cut -f1 -d ' ')
$ kubectl describe secret $SECRET_NAME -n kube-system | grep -E '^token' | cut -f2 -d':' | tr -d " "
eyJhbGc...-QmXA
출력된 토큰을 브라우저의 토큰 입력 창에 입력하면 클러스터 관리자 권한을 부여받은 사용자로 로그인할 수 있습니다.
퍼시스턴트 볼륨
퍼시스턴트 볼륨(Persistent Volume, PV)는 물리 저장 장치(volume)를 표현하는 Kubernetes의 자원입니다. 하나의 PV는 하나의 NHN Cloud Block Storage와 연결됩니다. 자세한 내용은 퍼시스턴트 볼륨 문서를 참고하세요.
PV를 파드에 연결해 사용하려면 퍼시스턴트 볼륨 클레임(Persistent Volume Claims, PVC) 객체가 필요합니다. PVC는 용량, 읽기/쓰기 모드 등 필요한 볼륨의 요구 사항을 정의합니다.
PV와 PVC로 사용자는 사용하고 싶은 볼륨의 속성을 정의하고, 시스템은 사용자의 요구 사항에 맞는 볼륨 리소스를 할당하는 방식으로 자원의 사용과 관리를 분리합니다.
PV/PVC의 생명 주기
PV와 PVC는 4단계의 생명 주기(life cycle)를 따릅니다.
-
프로비저닝(provisioning) 스토리지 클래스를 사용해 사용자가 직접 볼륨을 확보하고 PV를 생성(static provisioning)하거나 동적으로 생성(dynamic provisioning)할 수 있습니다.
-
바인딩(binding) PV와 PVC를 1:1로 바인딩합니다. 동적 프로비저닝으로 PV를 생성했다면 바인딩도 자동으로 수행됩니다.
-
사용(using) PV를 파드에 마운트해 사용합니다.
-
반환(reclaiming) 사용을 마친 볼륨을 회수합니다. 회수 방법은 삭제(Delete), 보존(Retain), 재사용(Recycle)이 있습니다.
| 방법 | 설명 |
|---|---|
| 삭제(Delete) | PV를 삭제할 때 연결된 볼륨을 함께 삭제합니다. |
| 보존(Retain) | PV를 삭제할 때 연결된 볼륨을 삭제하지 않습니다. 볼륨은 사용자가 직접 삭제하거나 재사용 할 수 있습니다. |
| 재사용(Recycle) | PV를 삭제할 때 연결된 볼륨을 삭제하지 않고 재사용할 수 있는 상태로 만듭니다. 이 방법은 사용 중단(deprecated) 되었습니다. |
스토리지 클래스(StorageClass)
프로비저닝을 하기 위해서는 먼저 스토리지 클래스가 정의되어 있어야 합니다. 스토리지 클래스는 어떤 특성으로 스토리지들을 분류할 수 있는 방법을 제공합니다. 스토리지 제공자(provisioner)에 대한 정보를 포함해 미디어의 종류나 가용성 영역 등을 설정할 수 있습니다.
스토리지 제공자(provisioner)
스토리지의 제공자 정보를 설정합니다. Kubernetes 버전에 따라 지원되는 스토리지 제공자 정보는 다음과 같습니다.
- v1.19.13 이전 버전: provisioner 필드를 반드시
kubernetes.io/cinder로 설정해야 합니다. - v1.20.12 이후 버전: provisioner 필드를
cinder.csi.openstack.org로 설정해 사용할 수 있습니다.
파라미터(parameter)
스토리지 클래스를 통해 다음의 파라미터를 설정할 수 있습니다.
- 스토리지 종류(type): 스토리지의 종류를 입력합니다.(미입력시 General HDD가 설정됩니다)
- General HDD: 스토리지 종류가 HDD로 설정됩니다.
- General SSD: 스토리지 종류가 SSD로 설정됩니다.
- 가용성 영역(availability): 가용성 영역을 설정합니다.(미입력시 무작위로 설정됩니다)
- 판교 리전: kr-pub-a 혹은 kr-pub-b
- 평촌 리전: kr2-pub-a 혹은 kr2-pub-b
볼륨 바인딩 모드(VolumeBindingMode)
볼륨 바인딩 모드는 볼륨 바인딩과 동적 프로비저닝의 시작 시점을 제어합니다. 이 설정은 스토리지 제공자가 cinder.csi.openstack.org인 경우에만 설정 가능합니다.
- Immediate: 퍼시스턴트 볼륨 클레임이 생성되는 즉시 볼륨 바인딩과 동적 프로비저닝이 시작됩니다. 퍼시스턴트 볼륨 클레임이 생성되는 시점에는 볼륨을 연결할 파드에 대한 사전 지식이 없는 상태입니다. 그래서 볼륨의 가용성 영역과 파드가 스케쥴링될 노드의 가용성 영역이 서로 다르게 되면 경우 파드가 정상 동작하지 않습니다.
- WaitForFirstConsumer: 퍼시스턴트 볼륨 클레임이 생성될 때는 볼륨 바인딩과 동적 프로비저닝을 하지 않습니다. 이 퍼시스턴트 볼륨 클레임이 처음으로 파드에 연결되면, 파드가 스케쥴링된 노드의 가용성 영역 정보를 기반으로 볼륨 바인딩과 동적 프로비저닝을 수행합니다. 따라서 Immediate 모드와 같은 볼륨의 가용성 영역과 인스턴스의 가용성 영역이 서로 달라 파드가 정상 동작하지 않는 경우가 발생하지 않습니다.
볼륨 확장 허용(allowVolumeExpansion)
생성된 볼륨의 확장 허용 여부를 설정합니다(미입력 시 false가 설정됩니다).
- True: 볼륨 확장을 허용합니다.
- False: 볼륨 확장을 허용하지 않습니다.
예시1
아래 스토리지 클래스 매니페스트는 v1.19.13 이전 버전을 사용하는 Kubernetes 클러스터에서 사용할 수 있습니다. 파라미터를 통해 가용성 영역과 볼륨 타입을 지정할 수 있습니다.
# storage_class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: sc-ssd
provisioner: kubernetes.io/cinder
parameters:
type: General SSD
availability: kr-pub-a
스토리지 클래스를 생성하고 확인합니다.
$ kubectl apply -f storage_class.yaml
storageclass.storage.k8s.io/sc-ssd created
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
sc-ssd kubernetes.io/cinder Delete Immediate false 3s
예시2
아래 스토리지 클래스 매니페시트는 v1.20.12 이후 버전을 사용하는 Kubernetes 클러스터에서 사용할 수 있습니다. 볼륨 바인딩 모드를 WaitForFirstConsumer로 설정해 퍼시스턴트 볼륨 클레임이 파드에 연결될 때 볼륨 바인딩과 동적 프로비저닝을 시작합니다.
# storage_class_csi.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-storageclass
provisioner: cinder.csi.openstack.org
volumeBindingMode: WaitForFirstConsumer
스토리지 클래스를 생성하고 확인합니다.
$ kubectl apply -f storage_class_csi.yaml
storageclass.storage.k8s.io/csi-storageclass created
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
csi-storageclass cinder.csi.openstack.org Delete WaitForFirstConsumer false 7s
정적 프로비저닝
정적 프로비저닝(static provisioning)은 사용자가 직접 블록 스토리지를 준비해야 합니다. NHN Cloud 웹 콘솔의 Storage > Block Storage 서비스 페이지에서 블록 스토리지 생성 버튼을 클릭해 PV와 연결할 블록 스토리지를 생성합니다. 블록 스토리지 가이드의 블록 스토리지 생성을 참고하세요.
PV를 생성하려면 블록 스토리지의 ID가 필요합니다. Storage > Block Storage 서비스 페이지의 블록 스토리지 목록에서 사용할 블록 스토리지를 선택합니다. 하단 정보 탭의 블록 스토리지 이름 항목에서 ID를 확인할 수 있습니다.
블록 스토리지와 연결할 PV 매니페스트를 작성합니다. spec.storageClassName에는 스토리지 클래스 이름을 입력합니다. NHN Cloud Block Storage를 사용하려면 spec.accessModes는 반드시 ReadWriteOnce로 설정해야 합니다. spec.presistentVolumeReclaimPolicy는 Delete 또는 Retain으로 설정할 수 있습니다.
v1.20.12 이후 버전의 클러스터는 cinder.csi.openstack.org 스토리지 제공자를 사용해야 합니다. 스토리지 제공자를 정의하기 위해 spec.annotations 하위에 pv.kubernetes.io/provisioned-by: cinder.csi.openstack.org 값을 지정하고, csi 항목 하위에 driver: cinder.csi.openstack.org 값을 지정합니다.
[주의] Kubernetes 버전에 맞는 스토리지 제공자가 정의된 스토리지 클래스를 설정해야 합니다.
# pv-static.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/provisioned-by: cinder.csi.openstack.org
name: pv-static-001
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: sc-default
csi:
driver: cinder.csi.openstack.org
fsType: "ext3"
volumeHandle: "e6f95191-d58b-40c3-a191-9984ce7532e5" # UUID of Block Storage
PV를 생성하고 확인합니다.
$ kubectl apply -f pv-static.yaml
persistentvolume/pv-static-001 created
$ kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv-static-001 10Gi RWO Delete Available sc-default 7s Filesystem
생성한 PV를 사용하기 위한 PVC 매니페스트를 작성합니다. spec.volumeName에는 PV의 이름을 지정해야 합니다. 다른 항목들은 PV 매니페스트의 내용과 동일하게 설정합니다.
# pvc-static.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-static
namespace: default
spec:
volumeName: pv-static-001
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: sc-default
PVC를 생성하고 확인합니다.
$ kubectl apply -f pvc-static.yaml
persistentvolumeclaim/pvc-static created
$ kubectl get pvc -o wide
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE
pvc-static Bound pv-static-001 10Gi RWO sc-default 7s Filesystem
PVC를 생성한 다음 PV의 상태를 조회해보면 CLAIM 항목에 PVC 이름이 지정되고, STATUS 항목이 Bound로 변경된 것을 확인할 수 있습니다.
$ kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv-static-001 10Gi RWO Delete Bound default/pvc-static sc-default 79s Filesystem
동적 프로비저닝
동적 프로비저닝(dynamic provisioning)은 스토리지 클래스에 정의된 속성을 참조하여 자동으로 블록 스토리지를 생성합니다. 동적 프로비저닝을 사용하기 위해서는 스토리지 클래스의 볼륨 바인딩 모드를 설정하지 않거나 Immediate로 설정해야 합니다.
# storage_class_csi_dynamic.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-storageclass-dynamic
provisioner: cinder.csi.openstack.org
volumeBindingMode: Immediate
동적 프로비저닝은 PV를 생성할 필요가 없습니다. 따라서 PVC 매니페스트에는 spec.volumeName를 설정하지 않습니다.
# pvc-dynamic.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-dynamic
namespace: default
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: csi-storageclass-dynamic
볼륨 바인딩 모드를 설정하지 않거나 Immediate로 설정하고 PVC를 생성하면 PV가 자동으로 생성됩니다. PV에 연결된 블록 스토리지도 자동으로 생성되며 NHN Cloud 웹 콘솔 Storage > Block Storage 서비스 페이지의 블록 스토리지 목록에서 확인할 수 있습니다.
$ kubectl apply -f pvc-dynamic.yaml
persistentvolumeclaim/pvc-dynamic created
$ kubectl get sc,pv,pvc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
storageclass.storage.k8s.io/csi-storageclass-dynamic cinder.csi.openstack.org Delete Immediate false 50s
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-1056949c-bc67-45cc-abaa-1d1bd9e51467 10Gi RWO Delete Bound default/pvc-dynamic csi-storageclass-dynamic 5s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/pvc-dynamic Bound pvc-1056949c-bc67-45cc-abaa-1d1bd9e51467 10Gi RWO csi-storageclass-dynamic 9s
[주의] 동적 프로비저닝으로 생성된 블록 스토리지는 웹 콘솔에서 삭제할 수 없습니다. 또한 클러스터를 삭제할 때 자동으로 삭제되지 않습니다. 따라서 클러스터를 삭제하기 전에 PVC를 모두 삭제해야 합니다. PVC를 삭제하지 않고 클러스터를 삭제하면 과금될 수 있습니다. 동적 프로비저닝을 생성된 PV의 reclaimPolicy는 기본적으로
Delete로 설정되기 때문에 PVC만 삭제해도 PV와 블록 스토리지가 삭제됩니다.
파드에 PVC 마운트
파드에 PVC를 마운트하려면 파드 매니페스트에 마운트 정보를 정의해야 합니다. spec.volumes.persistenVolumeClaim.claimName에 사용할 PVC 이름을 입력합니다. 그리고 spec.containers.volumeMounts.mountPath에 마운트할 경로를 입력합니다.
아래 예제는 정적 프로비저닝으로 생성한 PVC를 파드의 /usr/share/nginx/html에 마운트합니다.
# pod-pvc.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-with-static-pv
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
hostPort: 8082
protocol: TCP
volumeMounts:
- name: html-volume
mountPath: "/usr/share/nginx/html"
volumes:
- name: html-volume
persistentVolumeClaim:
claimName: pvc-static
파드를 생성하고 블록 스토리지가 마운트되어 있는지 확인합니다.
$ kubectl apply -f pod-static-pvc.yaml
pod/nginx-with-static-pv created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-with-static-pv 1/1 Running 0 50s
$ kubectl exec -ti nginx-with-static-pv -- df -h
Filesystem Size Used Avail Use% Mounted on
...
/dev/vdc 9.8G 23M 9.7G 1% /usr/share/nginx/html
...
NHN Cloud 웹 콘솔 Storage > Block Storage 서비스 페이지에서도 블록 스토리지의 연결 정보를 확인할 수 있습니다.
볼륨 확장
PersistentVolumeClaim (PVC) 개체를 편집하여 기존 볼륨의 크기를 조정할 수 있습니다. PVC 개체의 spec.resources.requests.storage항목의 수정을 통해 볼륨 사이즈를 변경할 수 있습니다. 볼륨 축소는 지원되지 않습니다. 볼륨 확장 기능을 사용하기 위해서는 StorageClass의 allowVolumeExpansion 속성이 True여야 합니다.
v1.19.13 이전 버전의 볼륨 확장
v1.19.13 이전 버전의 스토리지 제공자 kubernetes.io/cinder는 사용 중인 볼륨의 확장 기능을 제공하지 않습니다. 사용 중인 볼륨의 확장 기능을 사용하기 위해서는 v1.20.12 이후 버전의 cinder.csi.openstack.org 스토리지 제공자를 사용해야 합니다. 클러스터 업그레이드 기능을 통해 v1.20.12 이후 버전으로 업그레이드하여 cinder.csi.openstack.org 스토리지 제공자를 사용할 수 있습니다.
v1.19.13 이전 버전의 kubernetes.io/cinder 스토리지 제공자 대신 v1.20.12 이후 버전의 cinder.csi.openstack.org 스토리지 제공자를 사용하기 위하여 PVC의 어노테이션을 아래와 같이 수정해야 합니다.
- pv.kubernetes.io/bind-completed: "yes" > 삭제
- pv.kubernetes.io/bound-by-controller: "yes" > 삭제
- volume.beta.kubernetes.io/storage-provisioner: kubernetes.io/cinder > volume.beta.kubernetes.io/storage-provisioner:cinder.csi.openstack.org
- volume.kubernetes.io/storage-resizer: kubernetes.io/cinder > volume.kubernetes.io/storage-resizer: cinder.csi.openstack.org
- pv.kubernetes.io/provisioned-by:cinder.csi.openstack.org > 추가
아래는 수정된 PVC 예제입니다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
annotations:
pv.kubernetes.io/provisioned-by: cinder.csi.openstack.org
volume.beta.kubernetes.io/storage-provisioner: cinder.csi.openstack.org
volume.kubernetes.io/storage-resizer: cinder.csi.openstack.org
creationTimestamp: "2022-07-18T06:13:01Z"
finalizers:
- kubernetes.io/pvc-protection
labels:
app: nginx
name: www-web-0
namespace: default
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 310Gi
storageClassName: sc-ssd
volumeMode: Filesystem
volumeName: pvc-0da7cd55-bf29-4597-ab84-2f3d46391e5b
status:
accessModes:
- ReadWriteOnce
capacity:
storage: 300Gi
phase: Bound
v1.20.12 이후 버전의 볼륨 확장
v1.20.12 이후 버전의 스토리지 제공자 cinder.csi.openstack.org는 기본적으로 사용 중인 볼륨의 확장 기능을 지원합니다. PVC 개체의 spec.resources.requests.storage 항목을 원하는 값으로 수정하여 볼륨 사이즈를 변경할 수 있습니다.
NHN Cloud 서비스 연동
NHN Cloud Container Registry(NCR) 서비스 연동
NHN Cloud Container Registry에 저장한 이미지를 사용할 수 있습니다. 레지스트리에 저장된 이미지를 사용하기 위해서는 사용자 레지스트리에 로그인하기 위한 시크릿(secret)을 만들어야 합니다.
NHN Cloud (Old) Container Registry를 사용하려면 다음과 같이 시크릿을 생성해야 합니다.
$ kubectl create secret docker-registry registry-credential --docker-server={사용자 레지스트리 주소} --docker-username={NHN Cloud 계정 email 주소} --docker-password={서비스 Appkey 또는 통합 Appkey}
secret/registry-credential created
$ kubectl get secrets
NAME TYPE DATA AGE
registry-credential kubernetes.io/dockerconfigjson 1 30m
NHN Cloud Container Registry를 사용하려면 다음과 같이 시크릿을 생성해야 합니다.
$ kubectl create secret docker-registry registry-credential --docker-server={사용자 레지스트리 주소} --docker-username={User Access Key ID} --docker-password={Secret Access Key}
secret/registry-credential created
$ kubectl get secrets
NAME TYPE DATA AGE
registry-credential kubernetes.io/dockerconfigjson 1 30m
디플로이먼트 매니페스트 파일에 시크릿 정보를 추가하고, 이미지 이름을 변경하면 사용자 레지스트리에 저장된 이미지를 이용해 파드를 만들 수 있습니다.
# nginx.yaml
...
spec:
...
template:
...
spec:
containers:
- name: nginx
image: {사용자 레지스트리 주소}/nginx:1.14.2
...
imagePullSecrets:
- name: registry-credential
[참고] NHN Cloud Container Registry 사용 방법은 NHN Cloud Container Registry(NCR) 사용자 가이드 문서를 참고하세요.
NHN Cloud NAS 서비스 연동
NHN Cloud에서 제공하는 NAS 스토리지를 PV로 활용할 수 있습니다. NAS 서비스를 사용하기 위해서는 v1.20 이후 버전의 클러스터를 사용해야 합니다. NHN Cloud NAS 사용에 대한 자세한 내용은 NAS 콘솔 사용 가이드를 참고하세요.
[참고] NHN Cloud NAS 서비스는 현재(2024. 02.) 기준 일부 리전에서만 제공되고 있습니다. NHN Cloud NAS 서비스의 지원 리전에 대한 자세한 정보는 NAS 서비스 개요를 참고하세요.
모든 워커 노드에서 rpcbind 서비스 실행
NAS 스토리지를 사용하려면 모든 워커 노드에서 rpcbind 서비스를 실행해야 합니다. 모든 워커 노드에 접속한 뒤 아래 명령어를 통해 rpcbind 서비스를 실행합니다.
rpcbind 서비스 실행 명령어는 이미지 종류와 상관없이 동일합니다.
$ systemctl start rpcbind
강화된 보안 규칙을 사용하고 있는 클러스터의 경우 보안 규칙 추가가 필요합니다.
| 방향 | IP 프로토콜 | 포트 범위 | Ether | 원격 | 설명 |
|---|---|---|---|---|---|
| egress | TCP | 2049 | IPv4 | NAS IP 주소 | rpc의 NFS 포트, 방향: csi-nfs-node(worker node) -> NAS |
| egress | TCP | 111 | IPv4 | NAS IP 주소 | rpc의 portmapper 포트, 방향: csi-nfs-node(worker node) -> NAS |
| egress | TCP | 635 | IPv4 | NAS IP 주소 | rpc의 mountd 포트, 방향: csi-nfs-node(worker node) -> NAS |
csi-driver-nfs 설치
NHN Cloud NAS 서비스를 사용하기 위해 클러스터에 csi-driver-nfs 컴포넌트를 배포해야 합니다.
csi-driver-nfs는 NFS 스토리지에 새 하위 디렉터리를 생성하는 방식으로 동작하는 NFS 스토리지 프로비저닝을 지원하는 드라이버입니다. csi-driver-nfs는 스토리지 클래스에 NFS 스토리지 정보를 제공하는 방식으로 동작하여 사용자가 관리해야 하는 대상을 줄여 줍니다.
csi-driver-nfs를 사용하여 여러 개의 PV를 구성하는 경우 csi-driver-nfs가 NFS 스토리지 정보를 StorageClass에 등록하여 NFS-Provisoner pod를 구성할 필요가 없습니다.
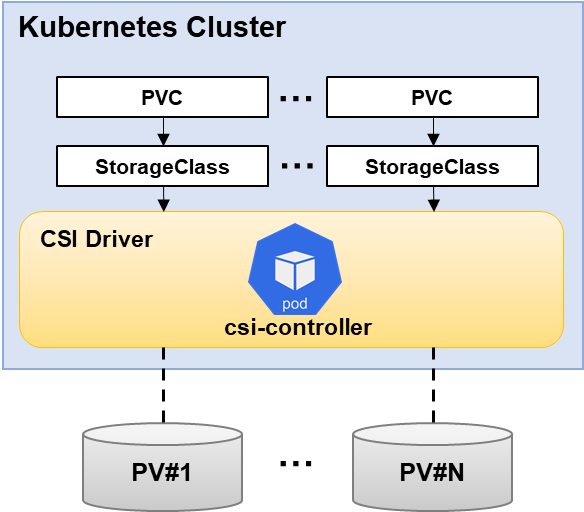
[참고] csi-driver-nfs 설치 스크립트의 내부 실행 과정에서 kubectl apply 명령이 수행됩니다. 따라서
kubectl명령어가 정상적으로 동작하는 상태에서 설치를 진행해야 합니다. csi-driver-nfs 설치 과정은 Linux 환경을 기준으로 작성되었습니다.
1. 클러스터 설정 파일 절대경로를 환경 변수에 저장합니다.
$ export KUBECONFIG={클러스터 설정 파일 절대경로}
2. ORAS 명령줄 도구를 사용하여 csi-driver-nfs 설치 패키지를 다운로드합니다.
ORAS(OCI Registry As Storage)는 OCI 레지스트리에서 OCI 아티팩트를 push 및 pull 하는 방법을 제공하는 툴입니다. ORAS installation을 참고하여 ORAS 명령줄 도구를 설치합니다. ORAS 명령줄 도구의 자세한 사용법은 ORAS docs를 참고하세요.
| 리전 | 인터넷 연결 | 다운로드 커맨드 |
|---|---|---|
| 한국(평촌) 리전 | O | oras pull ca6dde7d-kr2-registry.container.gov-nhncloud.com/container_service/oci/nfs-deploy-tool:v1 |
| X | oras pull private-ca6dde7d-kr2-registry.container.gov-nhncloud.com/container_service/oci/nfs-deploy-tool:v1 |
3. 설치 패키지를 압축 해제한 후 install-driver.sh {mode} 명령어를 사용하여 csi-driver-nfs 구성 요소를 설치합니다.
install-driver.sh 명령 실행 시 인터넷 연결이 가능한 클러스터는 public, 그렇지 않은 클러스터는 private을 입력해야 합니다.
[참고] csi-driver-nfs 컨테이너 이미지는 사내 NCR 레지스트리에서 관리되고 있습니다. 폐쇄망 환경에 구성된 클러스터는 인터넷에 연결되어 있지 않기 때문에 이미지를 정상적으로 받아오기 위해서는 Private URI를 사용하기 위한 환경 구성이 필요합니다. Private URI 사용법에 대한 자세한 내용은 NHN Cloud Container Registry(NCR) 사용자 가이드를 참고하세요.
아래는 인터넷망 환경에 구성된 클러스터에 설치 패키지를 이용하여 csi-driver-nfs를 설치하는 예시입니다.
$ tar -xvf nfs-deploy-tool.tar
$ ./install-driver.sh public
Installing NFS CSI driver, mode: public ...
serviceaccount/csi-nfs-controller-sa created
serviceaccount/csi-nfs-node-sa created
clusterrole.rbac.authorization.k8s.io/nfs-external-provisioner-role created
clusterrolebinding.rbac.authorization.k8s.io/nfs-csi-provisioner-binding created
csidriver.storage.k8s.io/nfs.csi.k8s.io created
deployment.apps/csi-nfs-controller created
daemonset.apps/csi-nfs-node created
NFS CSI driver installed successfully.
4. 구성 요소가 정상적으로 설치되었는지 확인합니다.
$ kubectl get pods -n kube-system
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system csi-nfs-controller-844d5989dc-scphc 3/3 Running 0 53s
kube-system csi-nfs-node-hmps6 3/3 Running 0 52s
$ kubectl get clusterrolebinding
NAME ROLE AGE
clusterrolebinding.rbac.authorization.k8s.io/nfs-csi-provisioner-binding ClusterRole/nfs-external-provisioner-role 52s
$ kubectl get clusterrole
NAME CREATED AT
clusterrole.rbac.authorization.k8s.io/nfs-external-provisioner-role 2022-08-09T06:21:20Z
$ kubectl get csidriver
NAME ATTACHREQUIRED PODINFOONMOUNT MODES AGE
csidriver.storage.k8s.io/nfs.csi.k8s.io false false Persistent,Ephemeral 47s
$ kubectl get deployment -n kube-system
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
kube-system coredns 2/2 2 2 22d
kube-system csi-nfs-controller 1/1 1 1 4m32s
$ kubectl get daemonset -n kube-system
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-system csi-nfs-node 1 1 1 1 1 kubernetes.io/os=linux 4m23s
프로비저닝 시 기존 NHN Cloud NAS 스토리지를 이용하는 방법
PV 매니페스트 작성 시 NAS 정보를 입력하거나 StorageClass 매니페스트에 NAS 정보를 입력해 기존 NAS 스토리지를 PV로 사용할 수 있습니다.
방법 1. PV 매니페스트 작성 시 NAS 스토리지 정보 정의
PV 매니페스트 작성 시 NHN Cloud NAS 스토리지 정보를 정의합니다. 설정 위치는 .spec 하위의 csi입니다.
- driver: nfs.csi.k8s.io를 입력합니다.
- readOnly: false를 입력합니다.
- volumeHandle: 클러스터 내에서 중복되지 않는 고유한 id를 입력합니다.
- volumeAttributes: NAS 스토리지의 연결 정보를 입력합니다.
- server: NAS 스토리지의 연결 정보 중 ip 부분의 값을 입력합니다.
- share: NAS 스토리지의 연결 정보 중 볼륨 이름 부분의 값을 입력합니다.
아래는 매니페스트 예제입니다.
# pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-onas
spec:
capacity:
storage: 300Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
csi:
driver: nfs.csi.k8s.io
readOnly: false
volumeHandle: unique-volumeid
volumeAttributes:
server: 192.168.0.98
share: /onas_300gb
PV를 생성하고 확인합니다.
$ kubectl apply -f pv.yaml
persistentvolume/pv-onas created
$ kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv-onas 300Gi RWX Retain Available 101s Filesystem
생성한 PV를 사용하기 위한 PVC 매니페스트를 작성합니다. spec.volumeName에는 PV의 이름을 지정해야 합니다. 다른 항목들은 PV 매니페스트의 내용과 동일하게 설정합니다.
# pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc-onas
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 300Gi
volumeName: pv-onas
PVC를 생성하고 확인합니다.
$ kubectl apply -f pvc.yaml
persistentvolumeclaim/pvc-onas created
$ kubectl get pvc -o wide
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE
pvc-onas Bound pv-onas 300Gi RWX 2m8s Filesystem
PVC를 생성한 다음 PV의 상태를 조회해보면 CLAIM 항목에 PVC 이름이 지정되고, STATUS 항목이 Bound로 변경된 것을 확인할 수 있습니다.
$ kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv-onas 300Gi RWX Retain Bound default/pvc-onas 3m20s Filesystem
방법 2. StorageClass 매니페스트 작성 시 NAS 정보 정의
StorageClass 매니페스트 작성 시 스토리지 제공자 정보 및 NHN Cloud NAS 스토리지 정보를 정의합니다.
- provisioner: nfs.csi.k8s.io를 입력합니다.
- parameters: NAS 스토리지의 연결 정보를 입력합니다.
- server: NAS 스토리지의 연결 정보 중 ip 부분의 값을 입력합니다.
- share: NAS 스토리지의 연결 정보 중 볼륨 이름 부분의 값을 입력합니다.
아래는 매니페스트 예제입니다.
# storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: onas-sc
provisioner: nfs.csi.k8s.io
parameters:
server: 192.168.0.81
share: /onas_300gb
reclaimPolicy: Retain
volumeBindingMode: Immediate
StorageClass를 생성하고 확인합니다.
$ kubectl apply -f storageclass.yaml
storageclass.storage.k8s.io/onas-sc created
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
onas-sc nfs.csi.k8s.io Retain Immediate false 3s
PV를 따로 생성할 필요가 없어 PVC 매니페스트만 작성합니다. PVC 매니페스트에는 spec.volumeName을 설정하지 않습니다.
# pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc-onas-dynamic
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 300Gi
storageClassName: onas-sc
볼륨 바인딩 모드를 설정하지 않거나 Immediate로 설정하고 PVC를 생성하면 PV가 자동으로 생성됩니다.
$ kubectl apply -f pvc.yaml
persistentvolumeclaim/pvc-onas created
$ kubectl get sc,pv,pvc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
storageclass.storage.k8s.io/onas-sc nfs.csi.k8s.io Retain Immediate false 25s
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-71392e58-5d8e-43b2-9798-5b59de34b203 300Gi RWX Retain Bound default/pvc-onas onas-sc 3s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/pvc-onas Bound pvc-71392e58-5d8e-43b2-9798-5b59de34b203 300Gi RWX onas-sc 4s
파드에 PVC를 마운트하려면 파드 매니페스트에 마운트 정보를 정의해야 합니다. spec.volumes.persistenVolumeClaim.claimName에 사용할 PVC 이름을 입력합니다. 그리고 spec.containers.volumeMounts.mountPath에 마운트 할 경로를 입력합니다.
아래는 생성한 PVC를 파드의 /tmp/nfs에 마운트하는 매니페스트 예제입니다.
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
namespace: default
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
volumeMounts:
- name: onas-dynamic
mountPath: "/tmp/nfs"
volumes:
- name: onas-dynamic
persistentVolumeClaim:
claimName: pvc-onas-dynamic
파드를 생성하고 NAS 스토리지가 마운트 되어 있는지 확인합니다.
$ kubectl apply -f deployment.yaml
deployment.apps/nginx created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-5fbc846574-q28cf 1/1 Running 0 26s
$ kubectl exec -it nginx-5fbc846574-q28cf -- df -h
Filesystem Size Used Avail Use% Mounted on
...
192.168.0.45:/onas_300gb/pvc-71392e58-5d8e-43b2-9798-5b59de34b203 270G 256K 270G 1% /tmp/nfs
...
프로비저닝 시 새로운 NHN Cloud NAS 스토리지를 생성하는 방법
StorageClass 및 PVC 매니페스트 작성 시 NAS 정보를 입력해 자동으로 생성된 NAS 스토리지를 PV로 사용할 수 있습니다.
StorageClass 매니페스트에 스토리지 제공자 정보 및 생성할 NAS 스토리지의 스냅숏 정책, 접근 제어 목록(ACL), 서브넷 정보를 정의합니다. * provisioner: nfs.csi.k8s.io를 입력합니다. * parameters: 입력 항목은 아래 표를 참고하세요. 파라미터 값에 다중 값을 정의하는 경우 ,를 이용하여 값을 구분합니다.
| 항목 | 설명 | 예시 | 다중 값 | 필수 | 기본값 |
|---|---|---|---|---|---|
| maxscheduledcount | 최대 저장 가능한 스냅숏 개수입니다. 최대 저장 개수에 도달하면 자동으로 생성된 스냅숏 중 가장 먼저 만들어진 스냅숏이 삭제됩니다. 1~20 사이의 숫자만 입력 가능합니다. | "7" | X | X | |
| reservepercent | 최대 저장 가능한 스냅숏 저장 용량입니다. 스냅숏 용량의 총합이 설정한 크기를 초과할 경우 모든 스냅숏 중 가장 먼저 만들어진 스냅숏이 삭제됩니다. 0~80 사이의 숫자만 입력 가능합니다. | "80" | X | X | |
| scheduletime | 스냅숏이 생성될 시각입니다. | "09:00" | X | X | |
| scheduletimeoffset | 스냅숏 생성 시각에 대한 오프셋입니다. UTC 기준이며 KST로 사용 시 +09:00 값을 지정합니다. | "+09:00" | X | X | |
| scheduleweekdays | 스냅숏 생성 주기입니다. 일요일부터 토요일까지 각각 숫자 0~6으로 표현됩니다. | "6" | O | X | |
| subnet | 스토리지에 접근할 서브넷입니다. 선택된 VPC의 서브넷만 선택할 수 있습니다. | "59526f1c-c089-4517-86fd-2d3dac369210" | X | O | |
| acl | 읽기, 쓰기 권한을 허용할 IP 또는 IP 대역 목록입니다. | "0.0.0.0/0" | O | X | 0.0.0.0/0 |
| onDelete | PVC 삭제 시 NAS 볼륨 삭제 여부입니다. | "delete" / "retain" | X | X | delete |
[참고] 스냅숏 파라미터 사용 시 관련된 모든 파라미터 값을 정의해야 합니다. 스냅숏 관련 파라미터는 아래와 같습니다. + maxscheduledcount + reservepercent + scheduletime + scheduletimeoffset + scheduleweekdays
[주의] 다중 서브넷 환경에서의 제약 사항
NAS 스토리지는 스토리지 클래스에 정의된 서브넷에 연결됩니다. 파드가 NAS 스토리지와 연동하기 위해서는 모든 워커 노드 그룹이 이 서브넷에 연결되어야 합니다.
아래는 매니페스트 예제입니다.
# storage_class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: sc-nfs
provisioner: nfs.csi.k8s.io
reclaimPolicy: Delete
volumeBindingMode: Immediate
parameters:
maxscheduledcount : "7"
reservepercent : "80"
scheduletime : "09:00"
scheduletimeoffset : "+09:00"
scheduleweekdays : "6"
subnet : "59526f1c-c089-4517-86fd-2d3dac369210"
acl : ""
PVC 매니페스트의 Annotation에 생성할 NAS 스토리지의 이름, 설명, 크기를 정의합니다. 입력 항목은 아래 표를 참고하세요.
| 항목 | 설명 | 예시 | 필수 |
|---|---|---|---|
| nfs-volume-name | 생성될 스토리지의 이름입니다. 스토리지 이름을 통해 NFS 접근 경로를 만듭니다. 이름은 100자 이내의 영문자와 숫자, 일부 기호('-', '_')만 입력할 수 있습니다. | "nas_sample_volume_300gb" | O |
| nfs-volume-description | 생성할 NAS 스토리지의 설명입니다. | "nas sample volume" | X |
| nfs-volume-sizegb | 생성할 NAS 스토리지의 크기입니다. GB 단위로 설정됩니다. 최소 300부터 최대 10,000까지 입력할 수 있습니다. | "300" | O |
아래는 매니페스트 예제입니다.
# pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-nfs
annotations:
nfs-volume-name: "nas_sample_volume_300gb"
nfs-volume-description: "nas sample volume"
nfs-volume-sizegb: "300"
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 50Gi
storageClassName: sc-nfs
StorageClass 및 PVC를 생성하고 확인합니다.
$ kubectl apply -f storage_class.yaml
storageclass.storage.k8s.io/sc-nfs created
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
sc-nfs nfs.csi.k8s.io Delete Immediate false 50s
PV를 따로 생성할 필요가 없어 PVC 매니페스트만 작성합니다. PVC 매니페스트에는 spec.volumeName을 설정하지 않습니다. 볼륨 바인딩 모드를 설정하지 않거나 Immediate로 설정하고 PVC를 생성하면 PV가 자동으로 생성됩니다. NAS 스토리지가 생성된 후 Bound되기까지 약 1분 정도 소요됩니다. NHN Cloud 콘솔 Storage > NAS 서비스 페이지에서도 생성된 NAS 스토리지의 정보를 확인할 수 있습니다.
$ kubectl apply -f pvc.yaml
persistentvolumeclaim/pvc-nfs created
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-a8ea2054-0849-4fe8-8207-ee0e43b8a103 50Gi RWX Delete Bound default/pvc-nfs sc-nfs 2s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/pvc-nfs Bound pvc-a8ea2054-0849-4fe8-8207-ee0e43b8a103 50Gi RWX sc-nfs 75s
파드에 PVC를 마운트하려면 파드 매니페스트에 마운트 정보를 정의해야 합니다. spec.volumes.persistenVolumeClaim.claimName에 사용할 PVC 이름을 입력합니다. 그리고 spec.containers.volumeMounts.mountPath에 마운트할 경로를 입력합니다.
아래는 생성한 PVC를 파드의 /tmp/nfs에 마운트하는 매니페스트 예제입니다.
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
namespace: default
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
volumeMounts:
- name: nas
mountPath: "/tmp/nfs"
volumes:
- name: nas
persistentVolumeClaim:
claimName: pvc-nfs
파드를 생성하고 NAS 스토리지가 마운트되어 있는지 확인합니다.
$ kubectl apply -f deployment.yaml
deployment.apps/nginx created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-9f448b9f7-xw92w 1/1 Running 0 12s
$ kubectl exec -it nginx-9f448b9f7-xw92w -- df -h
Filesystem Size Used Avail Use% Mounted on
overlay 20G 16G 4.2G 80% /
tmpfs 64M 0 64M 0% /dev
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
192.168.0.57:nas_sample_volume_100gb/pvc-a8ea2054-0849-4fe8-8207-ee0e43b8a103 20G 256K 20G 1% /tmp/nfs
...
[참고] csi-driver-nfs는 프로비저닝 시 NFS 스토리지 내부에 subdirectory를 생성하는 방식으로 동작합니다. 파드에 PV를 마운트하는 과정에서 subdirectory만 마운트되는 것이 아니라 NFS 스토리지 전체가 마운트되기 때문에 애플리케이션이 프로비저닝된 크기만큼 볼륨을 사용하도록 강제할 수 없습니다.
목차
- Container > NHN Kubernetes Service(NKS) > 사용 가이드
- 클러스터
- Kubernetes 버전 지원 정책
- 클러스터 생성
- 클러스터 조회
- 클러스터 삭제
- 클러스터 OWNER 변경
- 노드 그룹
- 노드 그룹 조회
- 노드 그룹 생성
- 노드 그룹 삭제
- 노드 그룹에 노드 추가
- 노드 그룹에서 노드 삭제
- 노드 중지와 시작
- GPU 노드 그룹 사용
- 오토 스케일러
- 사용자 스크립트(old)
- 사용자 스크립트
- 인스턴스 타입 변경
- 커스텀 이미지를 워커 이미지로 활용
- 클러스터 관리
- kubectl 설치
- 설정
- 연결 확인
- CSR(CertificateSigningRequest)
- 승인 컨트롤러(admission controller) 플러그인
- 클러스터 업그레이드
- 클러스터 CNI 변경
- 클러스터 API 엔드포인트 IP 접근 제어 적용
- 워커 노드 관리
- 컨테이너 관리
- 네트워크 관리
- kubelet 사용자 정의 아규먼트 설정 기능
- 사용자 정의 containerd 레지스트리 설정 기능
- LoadBalancer 서비스
- 웹 서버 파드 생성
- LoadBalancer 서비스 생성
- 인터넷을 통한 서비스 테스트
- 로드 밸런서 상세 옵션 설정
- 인그레스 컨트롤러
- NGINX Ingress Controller 설치
- URI 기반 서비스 분기
- 호스트 기반 서비스 분기
- Kubernetes 대시보드
- 대시보드 서비스 공개
- 대시보드 엑세스 토큰
- 퍼시스턴트 볼륨
- PV/PVC의 생명 주기
- 스토리지 클래스(StorageClass)
- 정적 프로비저닝
- 동적 프로비저닝
- 파드에 PVC 마운트
- 볼륨 확장
- NHN Cloud 서비스 연동
- NHN Cloud Container Registry(NCR) 서비스 연동
- NHN Cloud NAS 서비스 연동